引言
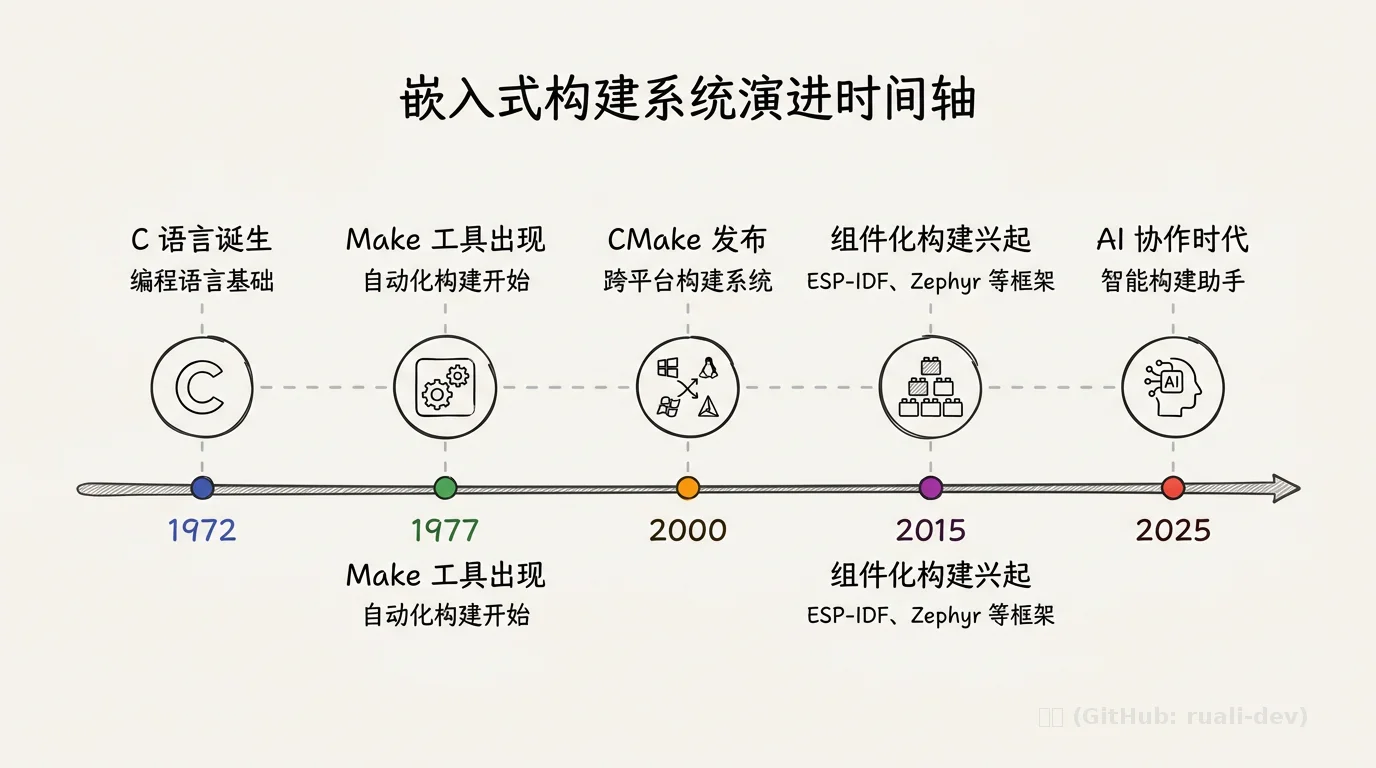
大一大二的时候接触单片机,学校社团教的是 Keil,用它开发过 51、STM32,后来也试过 CubeMX、RT-Thread Studio。最近开始接触直接用 CMake 开发的方式。我个人对嵌入式开发工具的变化挺有感触的。
第一章:IDE 主导的时代(1990 ~ 2015)
1.1 单片机 = 小工程
上世纪 90 年代到 2010 年代初,典型的嵌入式项目具有以下特征:
- 单 MCU,没有复杂的网络栈、文件系统;
- 代码量通常在 5k ~ 20k 行,几十个 .c 文件;
- 开发平台以 Windows 为主,团队规模小。
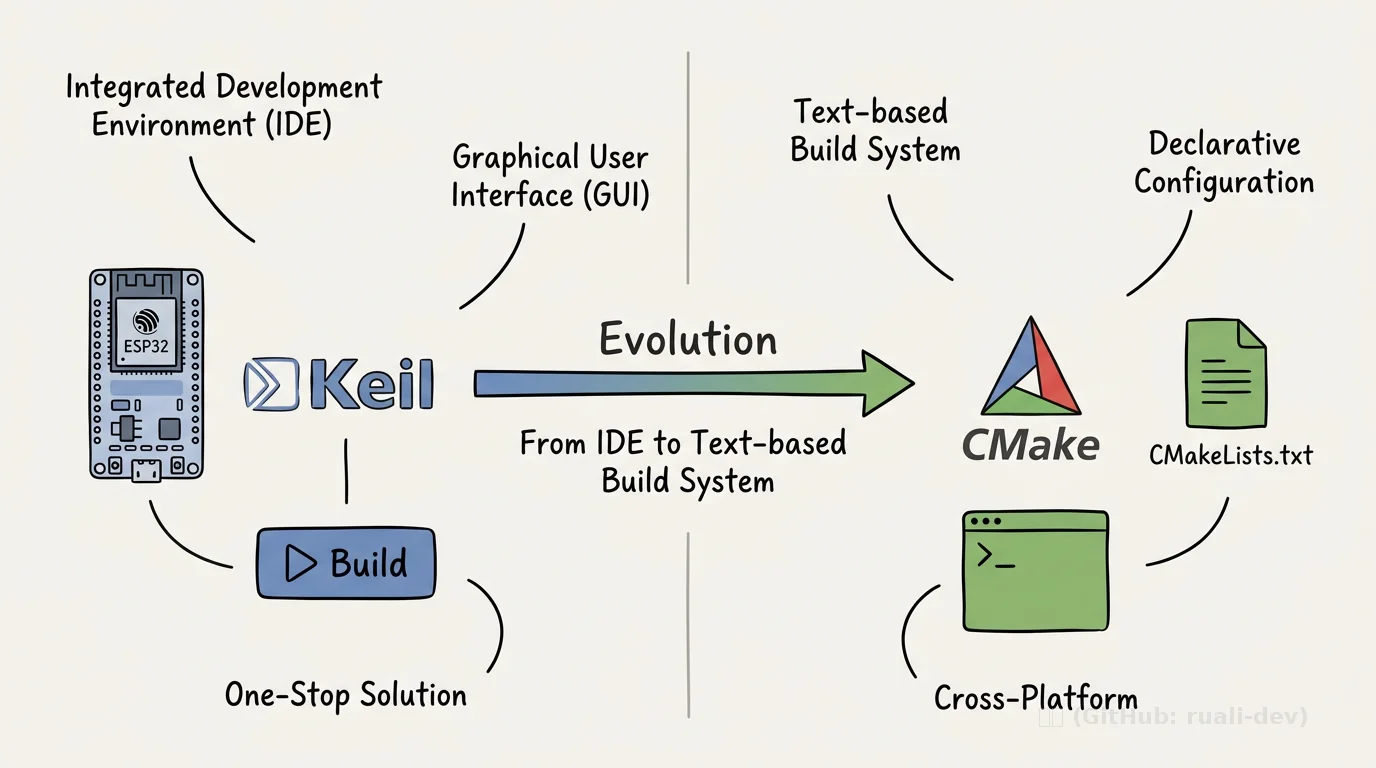
在这样的背景下,集成开发环境(IDE) 成为最自然的选择。Keil、IAR 等工具提供了一站式解决方案:
- ✔ 图形化添加文件、配置选项;
- ✔ 一键编译、下载、调试;
- ✔ 隐藏了底层的编译命令、链接顺序、库依赖。
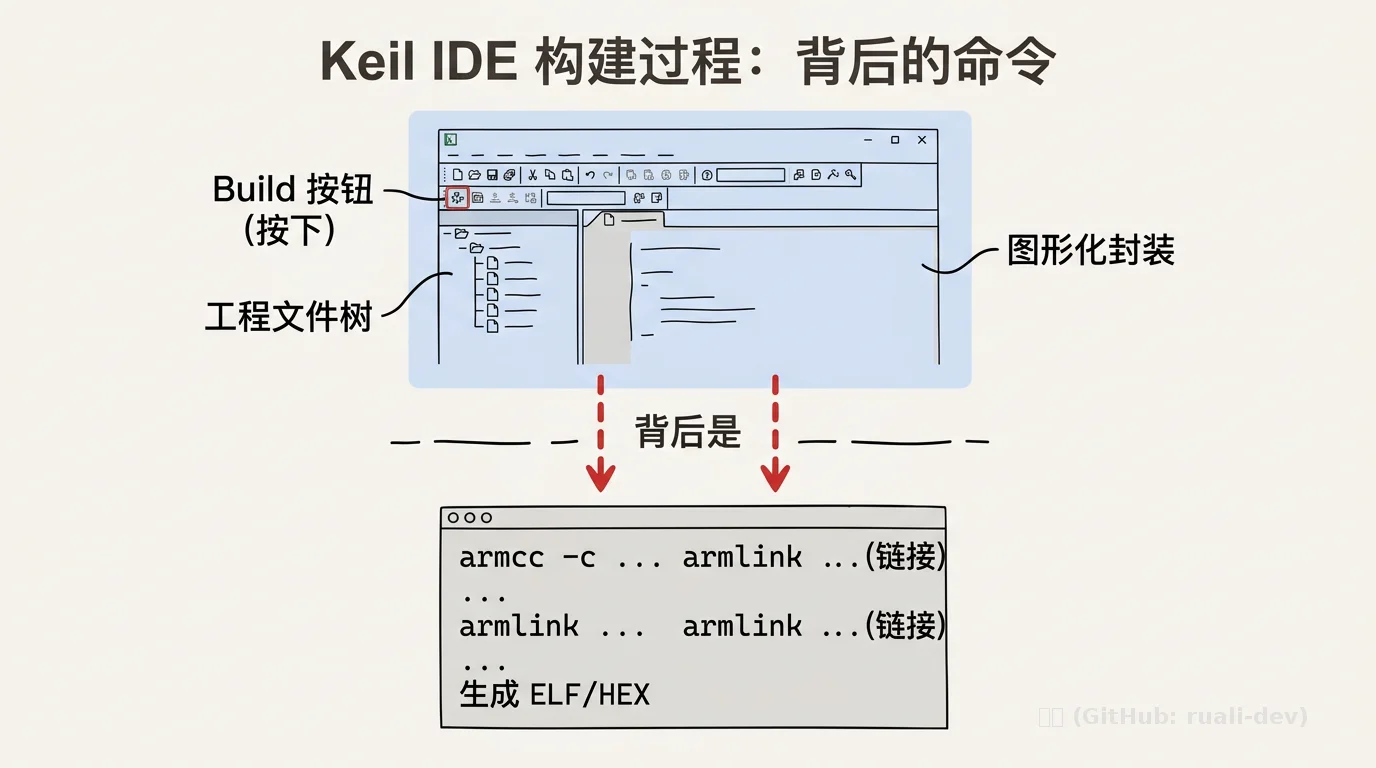
1.2 “黑箱”背后的构建流程
实际上,Keil 点击“Build”按钮后,背后依然执行了完整的编译链:
预处理 → 编译 → 汇编 → 链接 → 生成 ELF/HEX
只是这些步骤被 IDE 封装 了起来。开发者看不到 armcc、armlink 的具体参数,也不需要关心 -I、-L、-l 等选项。这种“黑箱”操作降低了入门门槛,让初学者能够快速点亮 LED、驱动外设。
然而,这也导致了很多嵌入式工程师直到毕业都没见过 Makefile,更不用说理解链接脚本、依赖传播等概念。
第二章:文本构建系统的回归(2015 ~ 今)
2.1 工程规模爆炸:从“单片机”到“微型系统”
2015 年前后,物联网(IoT)浪潮兴起,嵌入式项目的复杂度发生了质变:
- 功能扩展:Wi‑Fi、BLE、TCP/IP、文件系统、OTA、图形界面(LVGL)等成为标配;
- 代码量激增:从几十个文件增加到数百个文件,多个模块、子库需要管理;
- 跨平台协作:Linux/macOS 开发环境普及,GitHub 成为开源协作的主要平台;
- 自动化需求:持续集成(CI)要求构建过程能够脚本化、容器化。
此时,IDE 的局限性暴露无遗:
- ❌ 工程文件(.uvproj、.ewp)难以进行版本控制,多人协作易冲突;
- ❌ 无法在无 GUI 的服务器上运行,不适合 CI/CD 流水线;
- ❌ 跨平台支持弱,难以在 Linux 环境下无缝构建。
2.2 文本构建系统的优势
文本构建系统(Make、CMake、Ninja)恰恰弥补了上述缺陷:
- ✅ 纯文本文件,易于版本管理、diff/merge;
- ✅ 可通过命令行调用,完美适配 CI 流程;
- ✅ 跨平台生成对应的构建文件(Makefile、Visual Studio 工程、Xcode 工程)。
于是,“IDE 只是构建系统的前端” 成为新趋势。VSCode、CLion、ESP‑IDF 插件等编辑器/IDE 都转而调用底层的 CMake 来执行实际构建。
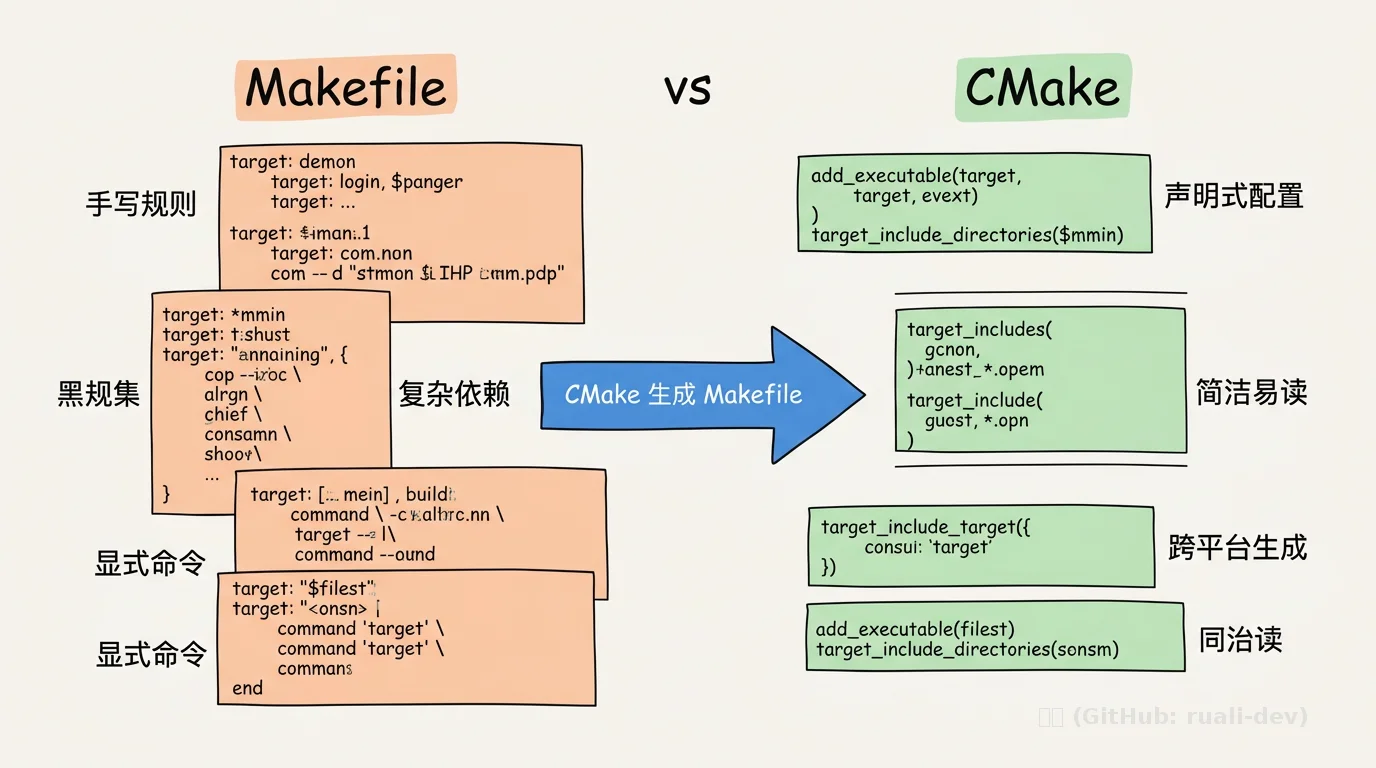
2.3 CMake 成为事实标准
CMake 诞生于 2000 年,初衷是 “写一次构建逻辑,生成多平台构建文件”。它并不是编译器,而是一个 “规则生成器”:
add_executable(app main.c)
target_include_directories(app PRIVATE include)
target_link_libraries(app foo)
CMake 解析这些声明,生成对应的 gcc/ld 命令(或 Ninja 规则)。这种 声明式 的写法比手写 Makefile 更简洁、更易维护。
第三章:核心概念解析
3.1 静态库与链接
当项目拆分为多个模块时,最常见的组织方式是将每个模块编译成 静态库(.a 文件)。链接阶段,链接器(ld)将这些库中的目标文件(.o)提取出来,合并到最终的可执行文件中。
链接错误(undefined reference) 本质上只有两类原因:
- 库没有被链接进来:依赖声明缺失或链接顺序错误;
- 符号被裁剪掉了:条件编译(#ifdef)或配置开关导致该符号未被编译。
3.2 Kconfig:功能开关系统
Kconfig 源自 Linux 内核,用于管理大规模软件的功能裁剪。在嵌入式框架(如 ESP‑IDF、Zephyr)中,它通过 menuconfig 界面生成 .config 文件,其中定义了大量的 CONFIG_XXX 变量。
这些变量会:
- 通过
-D宏定义传递给编译器,控制条件编译; - 在 CMake 中作为条件判断,决定是否编译某个组件。
例如,关闭 Bluetooth 选项后,相关代码和库都不会参与构建,从而减少固件体积。
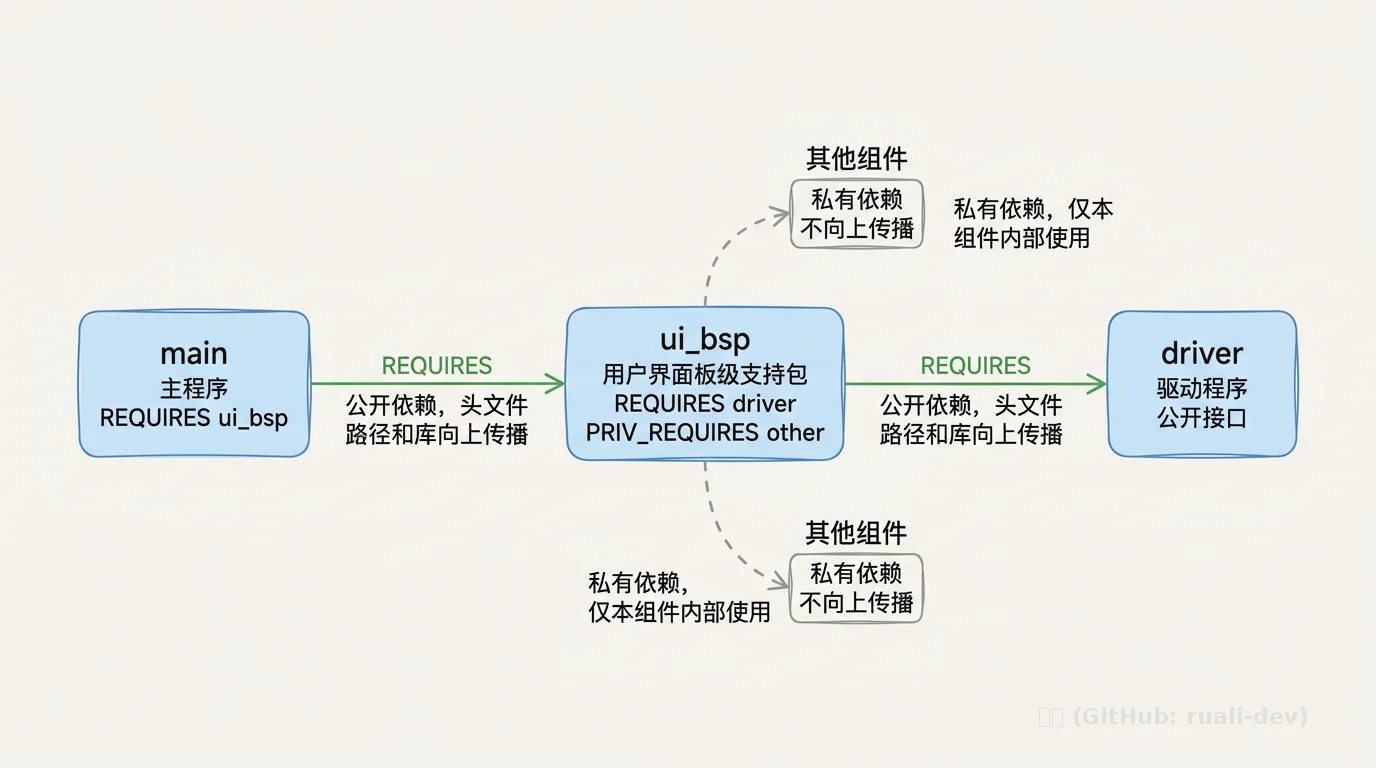
3.3 组件化构建与依赖传播
ESP‑IDF 将 CMake 封装为 组件模型。每个目录(如 components/xxx、main)都是一个组件,通过 idf_component_register 声明其源文件、依赖关系。
依赖分为两种:
- REQUIRES:公开依赖,头文件路径和库会向上传播;
- PRIV_REQUIRES:私有依赖,仅本组件内部使用。
这种设计保证了依赖图的清晰,避免了隐式的全局包含路径,也使得 “头文件在公开接口中 include,就必须用 REQUIRES” 成为一条铁律。
第四章:现代嵌入式构建的全景图
今天的嵌入式构建流程已经形成一条清晰的流水线:
Kconfig(功能开关)
↓
生成 sdkconfig
↓
CMake 读取 sdkconfig
↓
决定编译哪些组件、定义哪些宏
↓
生成 Ninja 规则
↓
gcc/ld 编译与链接
↓
生成 ELF 并烧录
这一套体系不仅用于 ESP‑IDF,在 Zephyr、NuttX、Android 甚至 Linux 内核等大型项目中都有类似实现。构建系统 + 配置系统 已经是现代工业软件的基础组件。
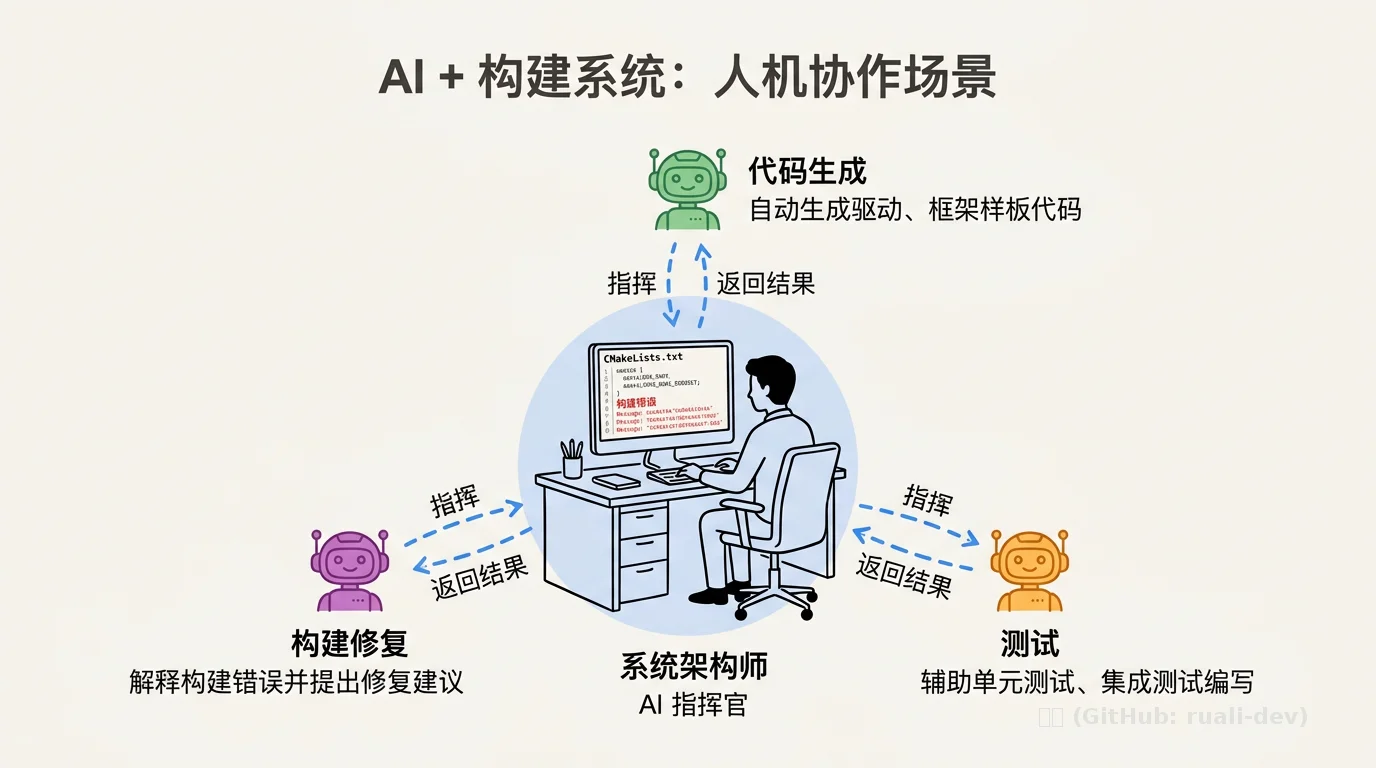
第五章:AI + 构建系统的协作趋势
5.1 AI 正在成为开发流程的一部分
近期行业调查显示,超过 80% 的开发团队已经在使用 AI 工具辅助代码生成、测试、文档等工作。在嵌入式领域,AI 的应用尤其明显:
- ✅ 自动生成驱动、框架样板代码;
- ✅ 解释构建错误并提出修复建议;
- ✅ 辅助单元测试、集成测试的编写;
- ✅ 甚至自动调优 PID 等控制参数。
5.2 人机协同的新模式
AI 不会取代嵌入式工程师,而是改变其工作方式。工程师的角色逐渐从 “每行代码的编写者” 转向 “系统架构师与 AI 指挥官”。
以修复构建依赖为例:工程师不再手动翻阅每个 CMakeLists.txt,而是指示 AI 扫描整个项目,将 public header 包含的依赖统一改为 REQUIRES。AI 负责机械性、重复性的细节,工程师把控整体结构与质量。
5.3 未来展望:Agentic Pipelines
学术界已提出 “Agentic Pipelines” 的概念——多个智能体在软件工程全生命周期中协作,分别负责代码生成、测试、重构、文档等任务,人类则进行监督、指导和最终决策。
这种模式将进一步放大工程师的效能,让团队能够管理更庞大、更复杂的嵌入式系统。
结语
嵌入式构建系统的演化,本质上是 软件工程工业化 的缩影:
- 从手工作坊(手写编译命令)到流水线(IDE 封装);
- 再到自动化生产线(CMake + Ninja + CI);
- 如今正在迈向 智能化协作(AI + 人类架构师)。
理解这套体系,不仅能更快解决构建问题,还能帮我们看清技术发展的方向。毕竟,这些不起眼的基础设施,才是真正支撑着现代数字世界的东西。
这篇文章是和 AI 对话整理出来的,感谢 Codex 帮忙处理了不少机械性的修复工作。
保持好奇,继续折腾。