

PyTorch Tutorial 04 - Build the Neural Network
Build the Neural Network — PyTorch Tutorials 2.10.0+cu128 documentation
本文是 PyTorch 官方 Tutorial 中 Build the Neural Network 部分的学习记录
设置加速器(如GPU)
- 在 加速器(如 CUDA、MPS、MTIA 或 XPU)上训练模型。如果当前有可用的加速器,使用它。否则,将使用 CPU
device = torch.accelerator.current_accelerator().type if torch.accelerator.is_available() else "cpu"
print(f"Using {device} device")
- 为啥要加速器属于老生常谈此处不表。
搭建神经网络
代码:
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten() # 把 28×28 → 784 维向量
self.linear_relu_stack = nn.Sequential( # 按顺序跑的一串东西
nn.Linear(28*28,512), # 做线性变换(Wx + b)
nn.ReLU(), # 非线性激活(引入非线性,模型才能学复杂函数)
nn.Linear(512,512),
nn.ReLU(),
nn.Linear(512 , 10), # 输出 10 类的 logits
)
def forward(self,x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
We define our neural network by subclassing
nn.Module, and initialize the neural network layers in__init__. Everynn.Modulesubclass implements the operations on input data in theforwardmethod.通过
nn.Module来定义神经网络,并在__init__中初始化神经网络层。每个nn.Module子类都在forward方法中实现对输入数据的操作。
model = NeuralNetwork().to(device)
- 创建一个
NeuralNetwork的实例,将其移动到device
打印结构:
print(model)
结果:
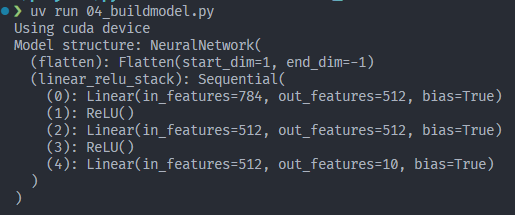
分析
此模型是一个3层MLP(多层感知机)
结构:输入层 → 隐藏层 → 输出层
| 组件 | 目的 |
|---|---|
| 输入层(Flatten) | 把图像展开,方便 Linear 处理 |
| 隐藏层 | 提取特征 |
| 激活函数 | 引入非线性,让模型学复杂模式 |
| 输出层 | 对应类别数(分类) |
神经网络本质上是 可学习的数学函数,通过参数训练逼近任务目标。
线性层+非线性激活让模型可以学任意函数族。
目前的这个网络,相当于一个带参数的函数 f(x; θ) 输入一张图像 → 输出一组 scores(logits)
而训练的目的就是:找到一组最优 θ(参数) 让 f(x; θ) 输出对训练数据预测正确
示例推理:
X = torch.rand(1, 28, 28, device=device)
logits = model(X)
pred_probab = nn.Softmax(dim=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")
结果:
Predicted class: tensor([4], device='cuda:0')
注意:
- 不应该直接 model.forward()
- model(x) = forward + 一堆自动管理逻辑
- 直接调 forward会跳过这些机制,以后高级功能会失效
具体剖析
定义一个3张28*28图像的minibatch
input_image = torch.rand(3,28,28)
Flatten层
flatten = nn.Flatten()
flat_image = flatten(input_image)
print(flat_image.size())
- 将每个 2D 28x28 图像转换为一个包含 784 个像素值的连续数组
Linear层
layer1 = nn.Linear(in_features=28*28, out_features=20)
hidden1 = layer1(flat_image)
print(hidden1.size())
- 线性层 是一个模块,它使用其存储的权重和偏置对输入应用线性变换。
ReLU层
print(f"Before ReLU: {hidden1}\n\n")
hidden1 = nn.ReLU()(hidden1)
print(f"After ReLU: {hidden1}")
- 非线性激活函数是创建模型输入与输出之间复杂映射的关键。 它们在线性变换之后应用,以引入非线性,帮助神经网络学习各种各样的现象。
- ReLU比较常用,也存在其他的。
- 为什么这里用ReLU:ReLU 正区间里导数 = 1 并且 计算快,而且ReLU 会把一半负数砍成 0 减少过拟合。
Softmax层
softmax = nn.Softmax(dim=1)
pred_probab = softmax(logits)
-
神经网络的最后一个线性层返回 logits - 即 [-infty, infty] 范围内的原始值 - 这些值被传递到 nn.Softmax 模块。逻辑值被缩放到 [0, 1] 范围内的值,代表模型对每个类别的预测概率。、
-
Softmax:
- 全部 >0
- 和 = 1
- 最大的更大
-
训练时一般 不要自己加 Softmax,nn.CrossEntropyLoss()内部有softmax
模型的参数
参数 = 可训练的权重(weights)和偏置(bias)。
完整流程:
初始化 W,b
↓
前向 → 算 loss
↓
反向 → 算 dW, db
↓
optimizer.step() → 更新 W,b
网络“学习”= 改这些数。
官方打印示例:
print(f"Model structure: {model}\n\n")
for name, param in model.named_parameters():
print(f"Layer: {name} | Size: {param.size()} | Values : {param[:2]} \n")