

PyTorch Tutorial 02 - Datasets & DataLoaders
Datasets & DataLoaders — PyTorch Tutorials 2.10.0+cu128 documentation
本文是 PyTorch 官方 Tutorial 中 Datasets & DataLoaders 部分的学习记录,主要整理 Dataset / DataLoader 的基本用法和个人理解。

PyTorch 提供了两个数据基元:
torch.utils.data.DataLoader和torch.utils.data.Dataset,允许您使用预加载的数据集以及您自己的数据。Dataset存储样本及其对应的标签,而DataLoader在Dataset周围包装一个可迭代对象,以便轻松访问样本。
简单来说,Dataset就是数据集,Dataloader就是数据加载器,一个负责数据集的组织,一个负责模型训练时候数据的加载
加载数据集
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
# 加载数据集
training_data = datasets.FashionMNIST(
root= "data", # root 是存储训练/测试数据的路径(相对路径)
train= True, # 选择加载/下载训练那一份
download=True, # 如果数据在 root 处不可用,则从互联网下载数据。
transform=ToTensor() # 取数据的时候自动预处理
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
可视化数据集
We can index Datasets manually like a list: training_data[index]. We use matplotlib to visualize some samples in our training data.
- 可以像列表一样手动索引 Datasets :training_data[index]。 可以使用 matplotlib 来可视化训练数据中的一些样本
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(training_data), size=(1,)).item()
img, label = training_data[sample_idx]
figure.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()

自定义数据集
A custom Dataset class must implement three functions: init, len, and getitem. Take a look at this implementation; the FashionMNIST images are stored in a directory
img_dir, and their labels are stored separately in a CSV fileannotations_file.
自定义 Dataset 类必须实现三个函数:init、len 和 getitem。 请查看此实现;FashionMNIST 图像存储在目录img_dir中,其标签则单独存储在 CSV 文件annotations_file中。
示例模板代码:
import os
import pandas as pd
from torchvision.io import decode_image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self , annotations_file , img_dir , transform=None , target_transform = None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self,idx):
img_path = os.path.join(self.img_dir , self.img_labels.iloc[idx , 0])
image = decode_image(img_path)
label = self.img_labels.iloc[idx , 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image , label
- init 负责读取标注文件、保存路径和预处理函数。
- len负责返回数据集中的样本数量。
- getitem负责定义每次取数据和预处理
Dataloader
Dataloader把训练模型时候对数据集的常见操作封装成了api,本质就是一个“批量喂数据的迭代器”。
可以:
- 自动组 minibatch
- 打乱:shuffle=True
- 并行读取:num_workers
from torch.utils.data import DataLoader
# 可视化数据集
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=False)
# Display image and label.
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze() #把长度为 1 的维度去掉 只为了画图好看,训练别乱 squeeze
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
效果:
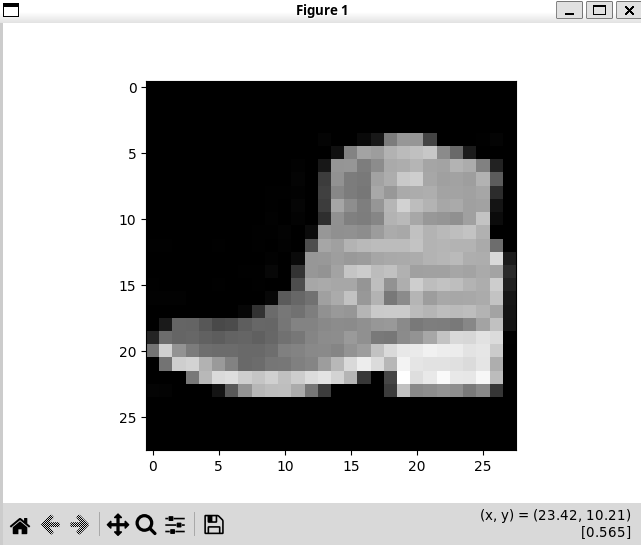
Feature batch shape: torch.Size([64, 1, 28, 28])
Labels batch shape: torch.Size([64])
Label: 9