

PyTorch Tutorial 05 - Optimizing Model Parameters
Optimizing Model Parameters — PyTorch Tutorials 2.10.0+cu128 documentation
本文是 PyTorch 官方 Tutorial 中 Optimizing Model Parameters 部分的学习记录,主要内容为训练、验证和测试模型
加载数据集和模型架构
- 见前文的FashionMNIST数据集和定义的mlp网络
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
training_data = datasets.FashionMNIST(
root= "data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
train_dataloader = DataLoader(training_data , batch_size=64)
test_dataloader = DataLoader(test_data , batch_size=64)
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28 , 512),
nn.ReLU(),
nn.Linear(512,512),
nn.ReLU(),
nn.Linear(512,10),
)
def forward(self , x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()
定义超参数
# 定义超参
learning_rate = 1e-3
batch_size = 64
epochs = 5
- learning_rate/学习率:在每个批次/轮次中更新模型参数的程度。小了学的慢大了可能炸。直观上说,等于梯度下降的时候一步走多远(见前文3B1B视频)
- Batch Size/批大小:在更新网络参数前,通过网络传播的数据样本数量
Batch Size 和显存(GPU 显存)关系非常大,而且这是最直接限制 batch size 的因素之一
Batch Size 也和 Learning Rate 强相关
Batch Size 不是越大越好(和学习效果有关)
OOM带不起大batch怎么办?可以用pytorch梯度累积假装大batch,后面为什么要清空梯度和这个操作有关系
- epochs/训练轮数:遍历数据集的迭代次数
定义损失函数
- 损失函数衡量所得结果与目标值之间的差异程度,而训练过程中我们要最小化的正是这个损失函数。
- 为了计算损失,我们使用给定数据样本的输入进行预测,并将其与真实的数据标签值进行比较。
# Initialize the loss function
loss_fn = nn.CrossEntropyLoss()
- 常见的损失函数包括用于回归任务的 nn.MSELoss(均方误差),以及用于分类任务的 nn.NLLLoss(负对数似然)。
- nn.CrossEntropyLoss 结合了
nn.LogSoftmax和nn.NLLLoss。
所以 nn.CrossEntropyLoss直接吃 logits(没 softmax 的原始输出)+ 类别标签
y(整型类标)
定义优化器
- 优化是在每个训练步骤中调整模型参数以减少模型误差的过程。优化算法定义了如何执行此过程
- 所有优化逻辑都封装在
optimizer对象中。这里使用 SGD 优化器(Stochastic Gradient Descent)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
通过注册模型中需要训练的参数,并传入学习率超参数来初始化优化器。
- 所有基于梯度的优化器需要 zero_grad()
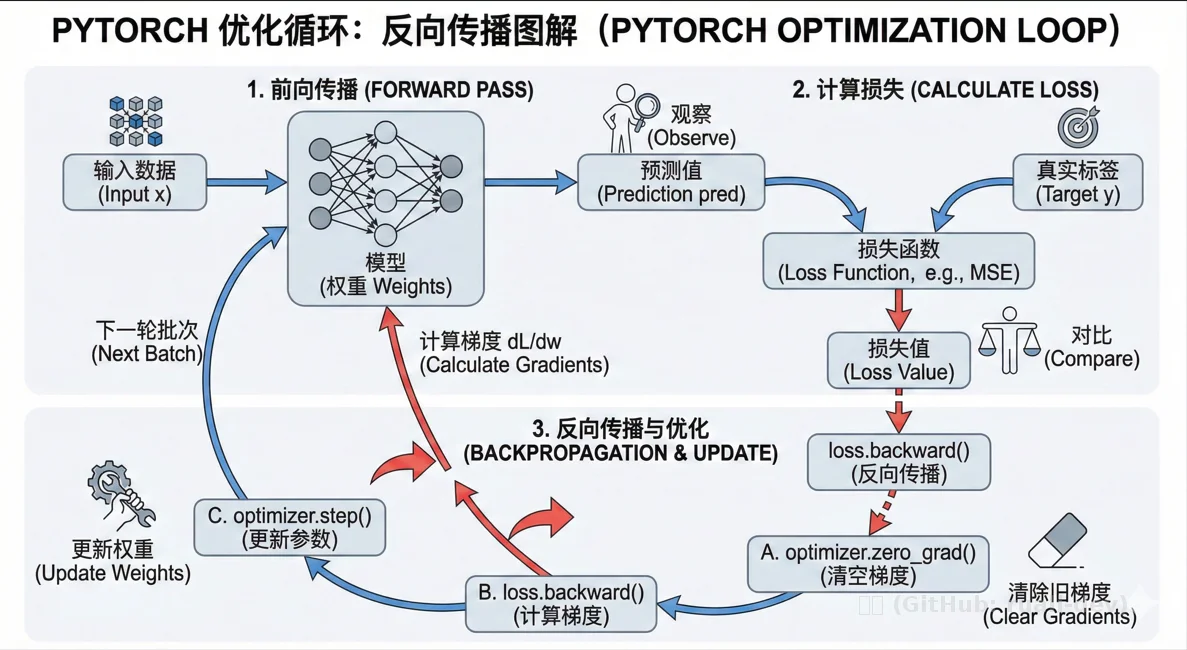
训练循环
其它代码见详细实现。这里讲下核心步骤
在训练循环内部,优化过程分为三个步骤:
- 调用
optimizer.zero_grad()来重置模型参数的梯度。梯度默认是累加的;(见上文batchsize,以及可以支持复杂loss和多任务学习)。为了防止重复计算,我们在每次迭代时显式地将它们清零。(忘了写可能导致loss爆炸) - 通过调用
loss.backward()来反向传播预测损失。(=自动求导 + 反向传播 + 把梯度存在grad里面, 注意:它只算,不更新参数。) - 调用
optimizer.step()来根据反向传播过程中收集到的梯度调整参数。
详细实现:
def train_loop(dataloader , model, loss_fn , optimizer):
size = len(dataloader.dataset)
model.train() # 开dropout和BatchNorm
for batch , (X ,y) in enumerate(dataloader):
pred = model(X) # 此轮预测输出
loss = loss_fn(pred , y) # 求误差
loss.backward() # 反向传播算梯度
optimizer.step() # 更新模型参数
optimizer.zero_grad() #清空梯度
if batch % 100 == 0:
loss , current = loss.item() , batch * batch_size + len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
训练模式和验证模式
model.train() 把模型切到 训练模式(training mode)。
主要影响:
Dropout
- train 模式:随机丢弃一部分神经元(起正则化作用)
- eval 模式:不丢弃,全部启用,并且按规则缩放(保证推理稳定)
BatchNorm(批归一化)
- train 模式:用当前 batch 的均值/方差做归一化,并更新 running_mean / running_var
- eval 模式:不再用当前 batch 的统计量,而是用训练时累计的 running_mean / running_var(保证推理一致)
所以:
- 训练前一般写 model.train()
- 验证/推理前一般写 model.eval()
完整实现
def train_loop(dataloader , model, loss_fn , optimizer):
size = len(dataloader.dataset)
model.train() # 开dropout和BatchNorm
for batch , (X ,y) in enumerate(dataloader):
pred = model(X) # 此轮预测输出
loss = loss_fn(pred , y) # 求误差
loss.backward() # 反向传播算梯度
optimizer.step() # 更新模型参数
optimizer.zero_grad() #清空梯度
if batch % 100 == 0:
loss , current = loss.item() , batch * batch_size + len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test_loop(dataloader, model, loss_fn):
# Set the model to evaluation mode - important for batch normalization and dropout layers
# Unnecessary in this situation but added for best practices
model.eval()
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
# Evaluating the model with torch.no_grad() ensures that no gradients are computed during test mode
# also serves to reduce unnecessary gradient computations and memory usage for tensors with requires_grad=True
with torch.no_grad():
for X, y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 这个 batch 里预测对了多少个。
test_loss /= num_batches # Avg loss = 所有 batch 的 loss 平均
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
# 定义超参
learning_rate = 1e-3
batch_size = 64
epochs = 5
# Optimization Loop
# Initialize the loss function
loss_fn = nn.CrossEntropyLoss() # 直接吃 logits(没 softmax 的原始输出)+ 类别标签 y(整型类标)。
# 优化:在每个训练步骤中调整模型参数以减少模型误差的过程。
# 优化器定义了如何执行此过程
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) # SGD 随机梯度下降 Stochastic Gradient Descent
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer)
test_loop(test_dataloader, model, loss_fn)
print("Done!")
结果:
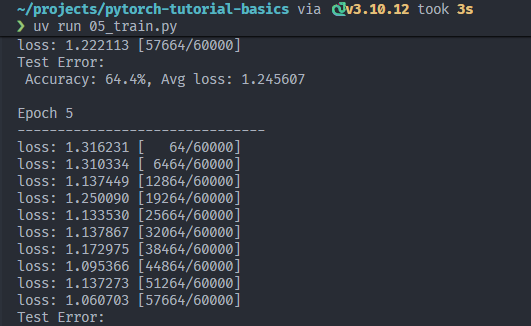
注意:本脚本未保存 checkpoint(未调用
torch.save),训练得到的参数只存在于当前运行进程内存中;重新运行脚本通常会重新初始化模型并从头训练。模型保存/加载见下一节。