

自动驾驶数据长尾分布问题:利用有世界先验的视频生成模型构建 Synthetic Data 实践
背景
经过漫长的打杂之后终于有稍微专业对口点的活了。
长尾问题天然存在于自动驾驶系统中。即使拥有大量数据,低频但重要的目标(例如突然横穿道路的小动物)仍然难以覆盖。在当前项目中,我们也遇到了类似问题。举个栗子,比如路上跑过去一条狗,这种情况数据集里面就很少(对于大厂来说,可能还能靠规模化采集慢慢覆盖;但对于研究院孵化的小公司来说,情况就没那么乐观了),难道你要真的抓一条狗过去反复采集吗?如果换成猫,换成鹅,甚至就是换个品种和花色呢。
实际上,近年来也有 YOLO-World 等开放词汇检测模型能够一定程度缓解类别扩展问题。
不过对于实际部署系统而言,训练数据覆盖度依然是无法绕开的核心问题。
但是这时候肯定会有人要说了,正常来说这种长尾case系统不知道正常啊,正常的数据闭环流程不应该是
线上运行
↓
模型低置信度
↓
保存图片
↓
人工审核
↓
发现狗
↓
加入数据集
但是问题在于,现在的无人车连个OTA都没有,更别说什么数据回传了,整条链路都不存在...
最初同事尝试的是一种典型的 Copy-Paste / Inpainting 思路:
真实纯背景图片 -> SAM2 + CLIP 道路区域提取 -> 在道路 mask 区域内随机采样候选中心点 -> SDXL + ControlNet Inpainting 目标插入 -> GroundingDINO 自动标注 -> 人工抽检 + 数据集合并
但是生成的图的效果....

(仅为示意图)
理论上流程完整,但实际生成结果暴露出了明显问题。
因此,这个问题后续转为由我继续探索。
视频生成模型合成长尾数据
一听到合成数据,这不是我们世界模型... 好吧,其实我当时第一反应就是Tesla之前的AI Day的那个分享,利用世界模型生成现实中很难见到的case,但是我实习的公司毕竟不是特斯拉,那怎么办呢,我想到了我国某个kill the game的视频生成模型。
相比普通图像生成或贴图,视频生成模型在训练过程中学到了某种"世界先验"——物体应当贴在地面上、远近应符合透视、目标运动应有连续轨迹、目标与背景的光照色调应一致。
基于这个认知,我提出改用图生视频模型生成"长尾目标事件":输入一张无人车前视道路图,让模型生成一只小狗从路边跑出、横穿道路或向镜头跑来的短视频,再从视频中抽取关键帧作为训练样本。
这里的关键区别:视频模型是在真实道路背景下,生成一个有运动、有接地、尺度和透视都合理的动态目标。它不是简单地把狗的像素贴进画面。
回到实际工作:起初团队对于直接调用商业视频生成模型是有顾虑的:一方面希望优先探索低成本方案;另一方面也担心生成效果是否足以支撑训练数据构建。不过考虑到新用户试用额度的存在,最终还是决定快速验证一下。
实验:Seedance2.0 / 即梦的生成与调优
一开始看了火山云平台,但是要api调用Seedance2.0你得先充值200块或者购买198.00的资源包才能调用。这么一比较那还是先用即梦算了。正好即梦有活动,1元可以体验7天会员,果断充了1块钱,现在账号里面有200+积分的额度。
即梦的使用方式非常简单,想知道怎么用自己进去就知道了。
先试着上传一张示意背景图,然后看看能不能生成个狗的长尾数据看看,
首轮提示词的要求包括:使用上传图片作为首帧、保持摄像机位置和视角不变、小狗需要真实尺度贴地运动、不改变背景、不加入镜头运动。

果然,不愧是kill the game的模型,这个效果我觉得不标AI很难看出来,至少从目标检测训练样本的视觉质量来看,已经具备进一步实验价值。
狗的尺度、接地关系、光照和整体风格基本合理,肉眼接近真实采集画面。唯一明显的问题是模型为了呈现更自然的狗,偷偷压低了摄像机高度,画面变成了低机位视角。
第二轮调优中,提示词策略从"描述狗"转向了"严格约束摄像机":保持原摄像机位置和视场、不降低、不移动、不缩放、不加入电影化镜头运动。同时补了英文提示词作为约束,明确标注这是 "autonomous vehicle front camera view"。
第二轮结果好了很多。狗与环境的关系自然,透视、尺度、接地和光照都更可信。不提前说的话,很难一眼看出这是合成数据。
抽帧实验:从视频到训练样本
生成 5 秒视频后,进入抽帧环节。
初始用 1 fps,5 秒得到约 6 张图。但狗的运动速度比较快,于是改为 2 fps。
2 fps 的结果:10 张图里约 6 张包含有效狗目标,有效率约 60%。
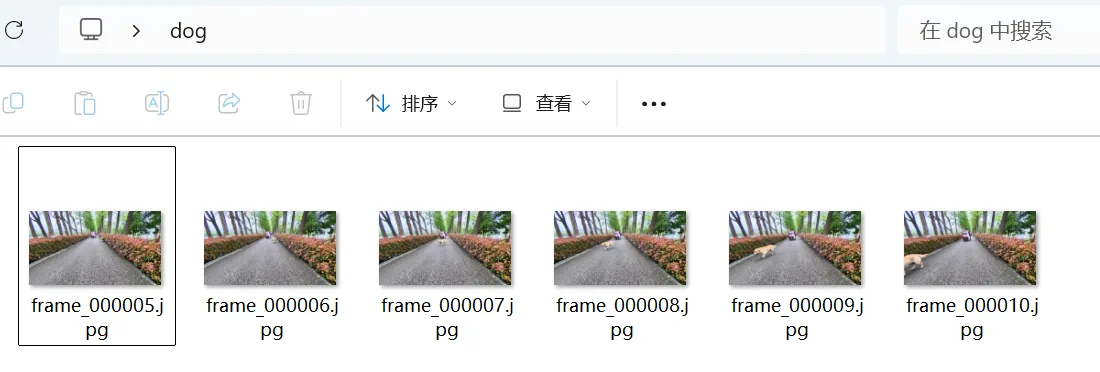
本地合成数据管线设想
基于实验结果,我开始搭一个轻量级合成数据流水线,目标是把"视频生成模型输出"变成"能直接用于目标检测训练的完整数据集"。
规划流程:
真实道路参考图 / Prompt
↓
视频生成模型生成长尾事件
↓
按 fps 抽帧
↓
清洗有效帧
↓
模型自动标注
↓
转换为 YOLO / COCO 格式
↓
加入训练集
↓
在真实验证集上评估召回 / mAP / 漏检率
当前已完成的第一步是抽帧模块。
Seedance / 即梦的效果没得说,但成本很现实。会员和积分价格不低,没优惠活动,基础会员就要几十块,然后会员会送点积分,用完了只能充积分,500积分=50块钱,排队和生成也需要很长时间,一个 5 秒视频seedance2.0需要70积分。api的话没试过一秒需要多少钱。如果要批量生成几百个长尾场景,费用会迅速上去。
后续方向是评估能不能用已有的 RTX 4090 工作站部署开源图生视频模型(如 Wan2.2-TI2V-5B),用本地模型替代部分闭源视频生成 API。截止下班前已经搭了一半,本地模型的效果只能下周上班再试试了。
阶段性结论
这次实验的核心判断得到了初步验证:视频生成模型相比传统贴图式合成数据,在自动驾驶长尾数据合成上有明显优势。
优势来自视频模型在训练中习得的空间理解能力。它生成的不是一只好看的狗,而是在真实道路场景中一个遵守物理和几何约束的完整目标事件——接地、尺度、透视、运动轨迹,这些都不是贴图能解决的。
不过目前为止,我们验证的仍然只是:视频生成模型能够生成足够真实的长尾目标事件。
而真正的问题还在后面:这些合成样本加入训练集后,是否能够提升真实验证集上的 Recall 和 mAP?是否能够改善模型对于长尾目标的识别能力?这也是下一阶段准备验证的问题。