

自动驾驶数据长尾分布问题:本地部署Wan2.2-TI2V-5B合成数据实践
前情
上篇文章里,用即梦(Seedance 2.0)验证了一件事:视频生成模型确实能生成足够真实的长尾目标事件——狗在道路上跑、接地关系合理、尺度和透视都靠谱。但商业 API 的成本放在那:一个 5 秒视频 70 积分(500 积分 = 50 元),要批量搞几百个场景的话,花费不低。而且数据要上传第三方平台,排队也要等。
所以接下来的方向:用已有的 RTX 4090 工作站,把开源图生视频模型部署到本地。看一下这个效果如何。
这篇文章记录的是本地部署 Wan2.2-TI2V-5B 的过程,以及围绕它搭的一条合成数据管线。
Wan2.2-TI2V-5B
Wan2.2 是阿里万相系列的开源视频生成模型。TI2V-5B 这个版本是统一的文生视频 + 图生视频架构,dense transformer。
从 HuggingFace 模型卡上看,规模大概是这样的:Transformer 部分约 5B 参数,T5 文本编码器约 6B,VAE 约 705M,加起来约 11B。模型权重在磁盘上占约 32GB。
这玩意对显存的要求比较具体。官方给的 RTX 4090 单卡数据:开模型 offload 跑 720P(1280×704),121 帧、50 步推理,生成 5 秒视频大约需要 9 分钟,显存占用约 22.9GB。24GB 显存刚好卡着边。
官方示例加载代码:
import torch
from diffusers import WanPipeline, AutoencoderKLWan
model_id = "Wan-AI/Wan2.2-TI2V-5B-Diffusers"
vae = AutoencoderKLWan.from_pretrained(model_id, subfolder="vae", torch_dtype=torch.float32)
pipe = WanPipeline.from_pretrained(model_id, vae=vae, torch_dtype=torch.bfloat16)
pipe.to("cuda")
output = pipe(
prompt="...",
image=image, # I2V 模式传入参考图
height=704, width=1280,
num_frames=121,
guidance_scale=5.0,
num_inference_steps=50,
).frames[0]
合成数据关系
单靠一个 Python 脚本调模型,改 prompt、调参数、排队跑、管理输出、抽帧……很快就乱了。所以花时间给整个流程做了个封装。
做了一个模仿即梦式平台的应用。技术栈:
- 后端 FastAPI + SSE。生成进度通过 Server-Sent Events 实时推送到前端。单次生成和批量生成共用同一个后台 worker 队列,串行处理、不会抢显存。
- 前端 React + Vite + Tailwind CSS。暗色主题,ChatGPT 风格的对话交互。
- 存储 JSON 文件。对话历史和批量任务状态直接落盘,暂时不引入数据库。
两个核心视图:
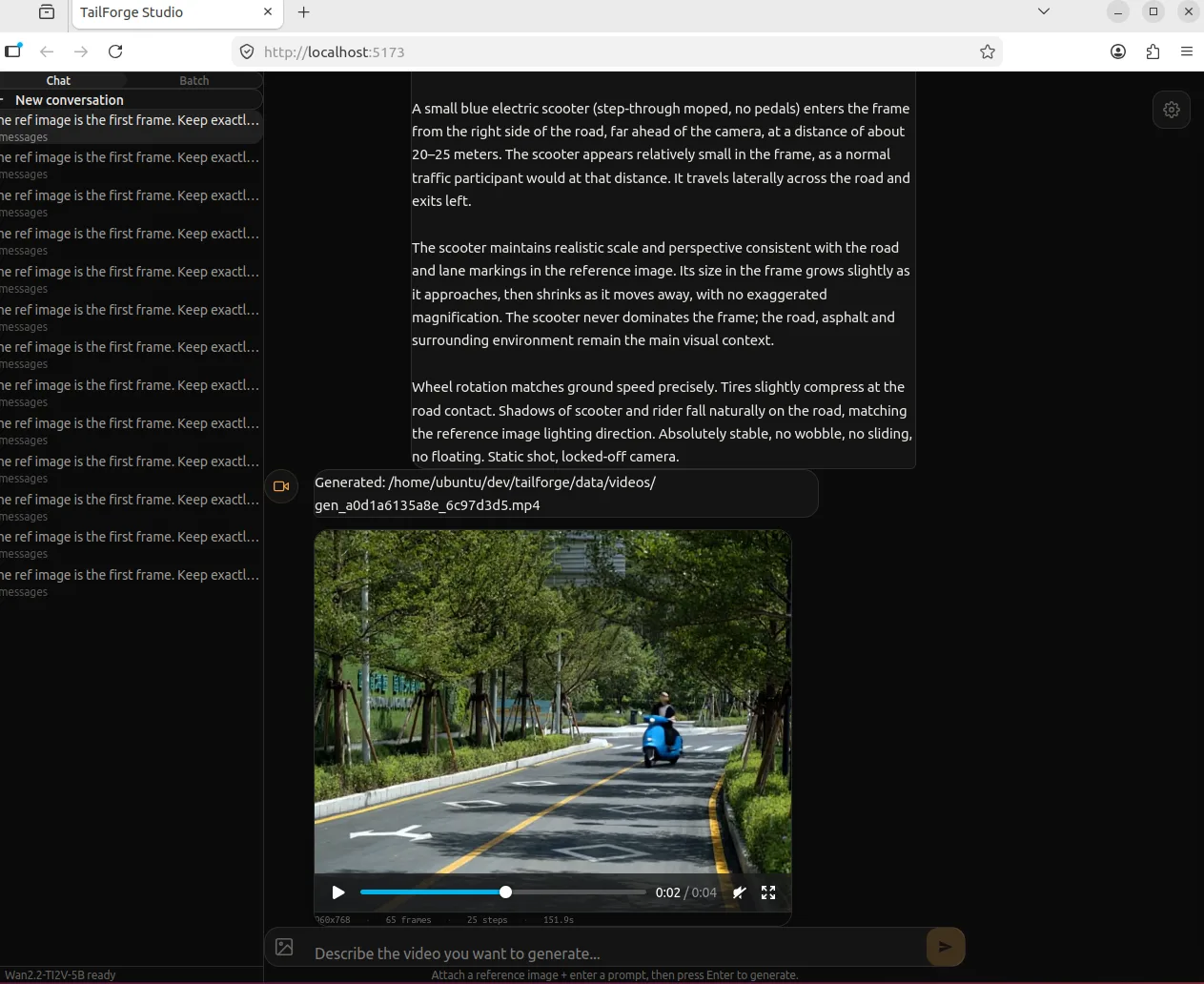
单对话生成。 上传参考图、输入 prompt,点生成。进度条实时推生成进度,生成的视频直接内嵌播放。适合快速试 prompt。
批量合成。 适用于不同场景批量生成数据,拖入多张背景图,写共享 prompt,设每张图的生成份数,一键入队。前端实时显示每个任务的状态(排队/运行中/完成/失败)。正经跑数据集的时候用——同一个 prompt 在多张不同背景上各生成若干段视频。
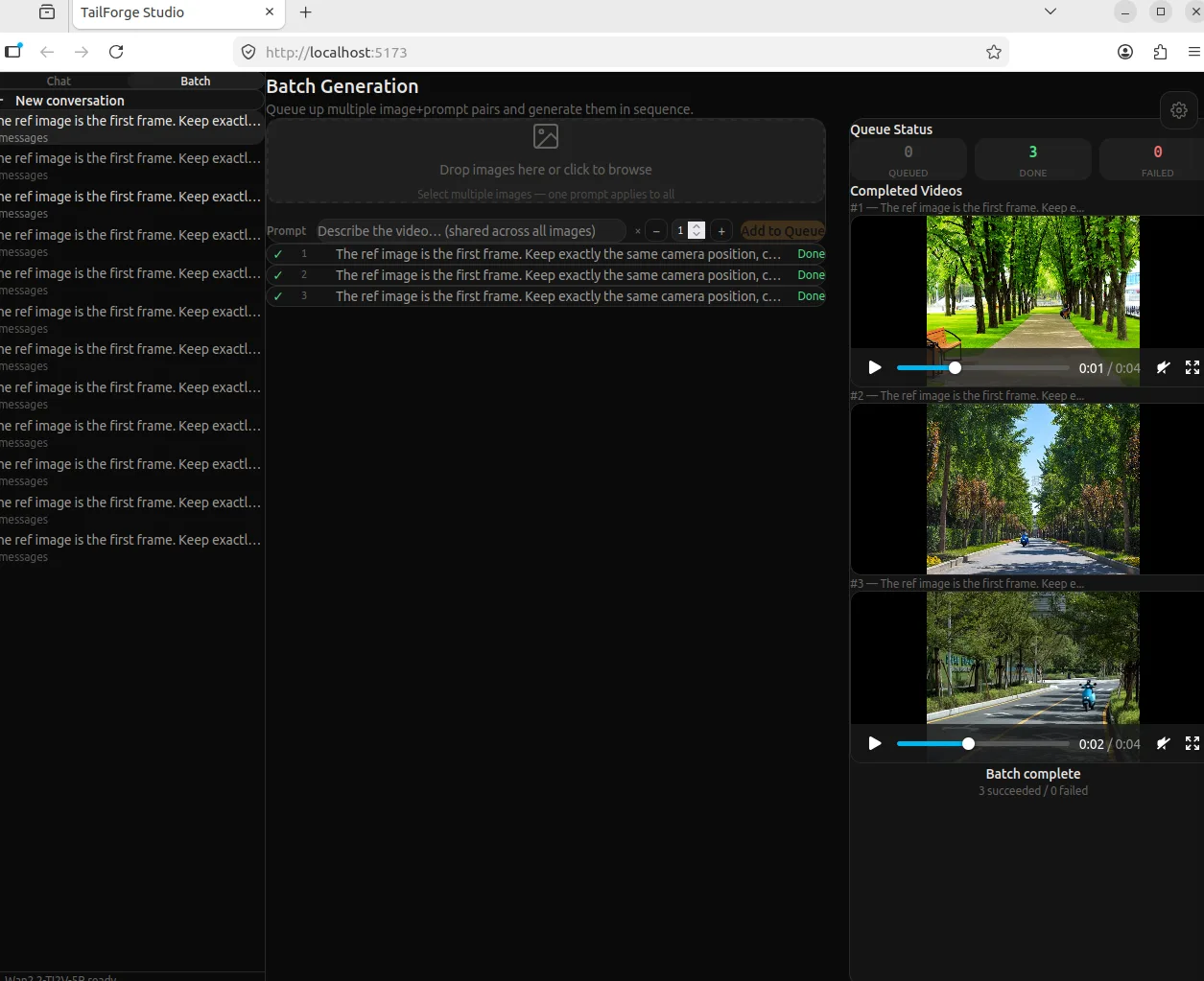
生成完成后,每个批次的视频可以一键抽帧:
视频 → 按 fps 抽 JPEG → data/frames/{batch_id}/{task_index}/frame_000001.jpg
抽帧模块基于 OpenCV,支持自定义 fps、跳过已有文件、批量处理。这一步直接对接到标注和训练流程。
生成效果
用同一张街景原图做了几轮测试。

视频效果:
生成电瓶车:
生成狗:
几个维度的观察:
首帧保持。 I2V模型在这件事上天然有优势。输入图片作为首帧,背景结构基本不变——道路、建筑、树木的位置和形状都稳住了,不会像纯 T2V模型那样搞出一个"看起来像但结构跑偏"的场景。
空间关系。 接地“基本合理”,透视与原始道路场景匹配。再差也比上篇的 SDXL + ControlNet Inpainting方案强。
但问题远比优点多,而且不是调调 prompt 能解决的:
- 语义理解弱。 prompt 遵循能力不够,有时候你想生成的东西就是生成不了。分词表也偏小,限制了能理解的概念范围。
- 画面质量一般。 整体偏糊,偶尔出现诡异的扭曲和形变。
- 变形生物:这是最头疼的一类——如果道路上有一个东西的轮廓(比如远处的人或路标),模型会把这个轮廓"变异"成你要求生成的目标。见过最离谱的一次是路边一个人突然变成了电动自行车。
- 无中生有:上面的那个生成狗的视频,可以看到是原图没车,但是突然就冒出来一辆车,可能是prompt太长,里面的autonomous vehicle被5B模型认为是生成目标。但是电动车的prompt更长也没见刷新这么明显的车子。可能是模型为了狗动作的合理性生成了一个车。
说白了,5B 参数量摆在那,开源模型在效果上确实碰不了商业API。所以目前只是验证了"本地能跑、能出图"这件事。这些生成的视频到底能不能用作训练数据,得抽帧、做数据清洗、然后喂给YOLO 跑一轮实验才知道。
小结
这次把上篇文章的思路从商业 API 验证推到了本地部署开源模型验证的阶段。
Wan2.2-TI2V-5B 在 RTX 4090 上能跑,配合我写的工具可以批量产出视频和抽帧。但整个链条还没有闭环——这些合成数据加到训练集里到底有没有用、能提升多少 mAP,还没有测过。这是下一步要回答的问题。