

摘要
在 ACT 和 DP 之后,我开始尝试 SmolVLA。选择 SmolVLA 的理由很简单——它是一个相对轻量的 VLA 模型,官方提供了预训练权重和训练配置,在有限算力下跑起来比较现实。本文记录从首次 smoke test、发现并修复 camera key 不兼容问题(自定义 Policy)、到 30k 四类 baseline 训练的完整过程。最终四类评测结果:top_short 8.33%、top_long 50.00%、pant_long 16.67%、pant_short 75.00%。
正文
1. 为什么选 SmolVLA
跑了 ACT 和 DP 之后,我对 LeHome 的数据结构和评测流程已经比较熟了。接下来的选择方向是:
- ACT 稳定但上限有限(top_short 58.33%),而且多类任务需要改配置
- DP 不稳,双臂协调性差,不好调
- 需要一个有一定预训练能力、能处理多类任务的模型
SmolVLA 是 LeRobot 生态里的 VLA(Vision-Language-Action)模型,有官方预训练权重 lerobot/smolvla_base,训练配置也现成。相比从头训练一个大模型,基于预训练权重做微调,在单张 L40 上更现实。
2. 数据准备
复用之前的流程。如果数据还没下:
hf download lehome/asset_challenge --repo-type dataset --local-dir Assets
hf download lehome/dataset_challenge_merged --repo-type dataset --local-dir Datasets/example
3. Smoke Test
3.1 配置
cp configs/train_smolvla.yaml configs/train_smolvla_ruali.yaml
编辑为 smoke 配置:
dataset:
repo_id: repo_smolvla_top_short
root: Datasets/example/top_short_merged
policy:
type: smolvla
device: cuda
push_to_hub: false
input_features:
observation.state:
type: STATE
shape: [12]
observation.images.camera1:
type: VISUAL
shape: [3, 480, 640]
observation.images.camera2:
type: VISUAL
shape: [3, 480, 640]
observation.images.camera3:
type: VISUAL
shape: [3, 480, 640]
output_features:
action:
type: ACTION
shape: [12]
output_dir: outputs/train/smolvla_top_short
batch_size: 32
steps: 10000
save_freq: 5000
log_freq: 1000
wandb:
enable: false
注意这里 camera 名字已经改成了 camera1/camera2/camera3 而不是 top_rgb/left_rgb/right_rgb。SmolVLA 的预训练权重里,图像特征期待的是这三个名字。
但是数据集里的实际键名是 top_rgb/left_rgb/right_rgb。这个不匹配后面会带来一系列问题。
3.2 第一次训练:feature name 不匹配
tmux new -s smolvla
conda activate lehome311
source .venv/bin/activate
cd /root/gpufree-data/lehome-challenge
lerobot-train \
--config_path=configs/train_smolvla_ruali.yaml \
--policy.path=lerobot/smolvla_base \
--policy.push_to_hub=false \
--policy.repo_id=ruali/smolvla-top-short-local
报错:
ValueError: Feature mismatch between dataset/environment and policy config.
- Missing features: ['observation.images.camera1', 'observation.images.camera2', 'observation.images.camera3']
- Extra features: ['observation.images.left_rgb', 'observation.images.right_rgb', 'observation.images.top_rgb']
Please ensure your dataset and policy use consistent feature names. If your dataset uses
different observation keys (e.g., cameras named differently), use the --rename_map argument...
报错信息其实已经把解决方案说清楚了——加 --rename_map。
3.3 修复:加 rename_map 训练
命令改为:
lerobot-train \
--config_path=configs/train_smolvla_ruali.yaml \
--policy.path=lerobot/smolvla_base \
--policy.push_to_hub=false \
--policy.repo_id=ruali/smolvla-top-short-local \
--rename_map='{"observation.images.top_rgb":"observation.images.camera1","observation.images.left_rgb":"observation.images.camera2","observation.images.right_rgb":"observation.images.camera3"}' \
2>&1 | tee logs/smolvla_top_short.log
这次成功了,10k smoke 顺利跑完。
4. 第一个大坑:评测时 camera key 不匹配
4.1 Smoke 评测失败
训练顺利,但评测出了问题:
python -m scripts.eval \
--policy_type lerobot \
--policy_path outputs/train/smolvla_top_short/checkpoints/last/pretrained_model \
--garment_type "top_short" \
--dataset_root Datasets/example/top_short_merged \
--num_episodes 1 \
--enable_cameras \
--save_video \
--video_dir outputs/eval_videos/smolvla_top_short_10k \
--device cpu
模型动作看起来毫无意义——几乎像随机动作。
4.2 找原因
回头看训练过程:训练时靠 rename_map 把 top_rgb / left_rgb / right_rgb 映射成 camera1 / camera2 / camera3 才能训起来。
但官方 scripts/eval_policy/lerobot_policy.py 里的 lerobot 评测路径,会先按 policy 的 input_features 过滤观测,只保留"名字已经匹配"的键。这段代码里没有 rename_map 处理。
所以环境给出来的 top_rgb/left_rgb/right_rgb 在评测时被直接过滤掉了——模型实际收到的观测里没有任何图像,自然动作就是盲猜了。
4.3 解决:写一个 Custom Policy
既然官方评测路径不支持 rename_map,那就自己写一个 policy adapter。
创建 scripts/eval_policy/custom_smolvla_policy.py:
import os
from typing import Dict, Optional
import numpy as np
from .registry import PolicyRegistry
from .lerobot_policy import LeRobotPolicy
@PolicyRegistry.register("custom_smolvla")
class CustomSmolVLAPolicy(LeRobotPolicy):
"""
SmolVLA adapter for LeHome custom evaluation.
What it does:
1. Loads your trained LeRobot/SmolVLA checkpoint.
2. Renames LeHome camera keys:
top_rgb / left_rgb / right_rgb
-> camera1 / camera2 / camera3
3. Reuses the official LeRobotPolicy preprocessing + inference pipeline.
"""
def __init__(
self,
model_path: Optional[str] = None,
device: str = "cuda",
**kwargs,
):
if model_path is None:
raise ValueError("Custom SmolVLA policy requires model_path.")
dataset_root = os.getenv(
"LEHOME_DATASET_ROOT",
"Datasets/example/top_short_merged",
)
task_description = os.getenv(
"LEHOME_TASK_DESCRIPTION",
"Bimanual garment manipulation",
)
super().__init__(
policy_path=model_path,
dataset_root=dataset_root,
task_description=task_description,
device=device,
)
self.rename_map = {
"observation.images.top_rgb": "observation.images.camera1",
"observation.images.left_rgb": "observation.images.camera2",
"observation.images.right_rgb": "observation.images.camera3",
}
print(
f"[CustomPolicy] Initialized. "
f"device={device}, model_path={model_path}, dataset_root={dataset_root}"
)
def reset(self):
super().reset()
def select_action(self, observation: Dict[str, np.ndarray]) -> np.ndarray:
remapped_obs = {}
for key, value in observation.items():
remapped_obs[self.rename_map.get(key, key)] = value
return super().select_action(remapped_obs)
然后在 scripts/eval_policy/__init__.py 里注册:
from .custom_smolvla_policy import CustomSmolVLAPolicy
__all__ = [
"BasePolicy",
"PolicyRegistry",
"LeRobotPolicy",
"CustomPolicy",
"DockerPolicy",
"CustomSmolVLAPolicy",
]
4.4 重新评测
export LEHOME_DATASET_ROOT=Datasets/example/top_short_merged
export LEHOME_TASK_DESCRIPTION="Bimanual garment manipulation"
mkdir -p outputs/eval_videos/smolvla_top_short_10k
mkdir -p logs
python -m scripts.eval \
--policy_type custom_smolvla \
--policy_path outputs/train/smolvla_top_short/checkpoints/last/pretrained_model \
--garment_type top_short \
--dataset_root Datasets/example/top_short_merged \
--num_episodes 1 \
--enable_cameras \
--save_video \
--video_dir outputs/eval_videos/smolvla_top_short_10k \
--device cpu \
2>&1 | tee logs/eval_smolvla_top_short_10k.log
这次评测正常了,模型的行为开始有意义了。
5. 从 10k → 30k 训练
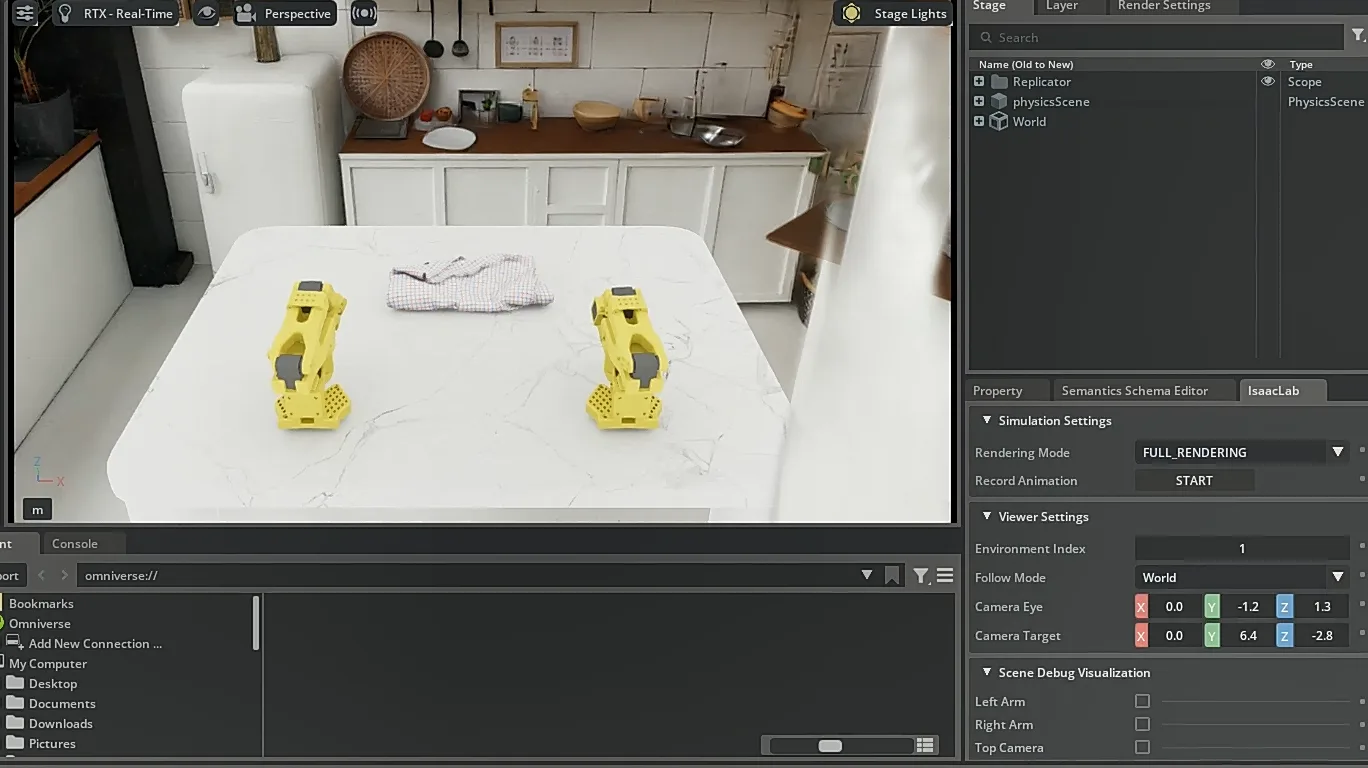
10k smoke summary 虽然全 failed,但看 GUI 画面感觉"有潜力"——双臂在朝正确的方向移动,比 DP 的左手偏置好太多了。决定继续训练。
5.1 Resume 到 30k
tmux new -s smolvla_resume
conda activate lehome311
source .venv/bin/activate
cd /root/gpufree-data/lehome-challenge
lerobot-train \
--config_path=outputs/train/smolvla_top_short/checkpoints/last/pretrained_model/train_config.json \
--resume=true \
--steps=30000 \
2>&1 | tee logs/smolvla_top_short_resume_to_30k.log
5.2 30k 评测结果
Total Episodes: 12
Average Return: 186.30 ± 100.63
Success Rate: 25.00%
Per-Garment:
Top_Short_Seen_5: 100.00%, Avg Return = 108.02
Top_Short_Seen_7: 100.00%, Avg Return = 111.47
Top_Short_Unseen_1: 100.00%, Avg Return = 134.98
(其余 9 个为 0.00%)
12 个 episode 中 3 个成功。这个成绩不高,只有 25%,但注意一个细节——成功的 episode 对应的是较低的 Avg Return(108、111、134),而失败的 episode 里有很多 Return 很高(428、345、214),说明模型在"做很多事情",但做的事情不总是对的。
6. Baseline 提交:四类 30k 训练
既然单类跑通了,这里时间跨度比较大,原因很多,但是主要的原因是,我其实更倾向于使用更强的底座模型,我当时是看到30k的smolVLA效果不好,打算换pi0.5试试,但是折腾了很久都没有弄出来,于是打算先提交个30k的smolVLA的基线。
Baseline提交需要训练四类 merged 数据。
6.1 配置
# train_smolvla_submit.yaml
dataset:
repo_id: repo_smolvla_submit_4types
root: Datasets/example/four_types_merged
policy:
type: smolvla
device: cuda
push_to_hub: false
input_features:
observation.state:
type: STATE
shape: [12]
observation.images.camera1:
type: VISUAL
shape: [3, 480, 640]
observation.images.camera2:
type: VISUAL
shape: [3, 480, 640]
observation.images.camera3:
type: VISUAL
shape: [3, 480, 640]
output_features:
action:
type: ACTION
shape: [12]
output_dir: outputs/train/smolvla_submit_4types
batch_size: 48
steps: 30000
save_freq: 5000
log_freq: 1000
wandb:
enable: false
这次 batch 直接上 48(L40 48G 能 hold 住),steps 30000,不用 rename_map 在配置里而是通过命令行传。
6.2 训练
tmux new -s smolvla_submit
conda activate lehome311
source .venv/bin/activate
lerobot-train \
--config_path=configs/train_smolvla_submit.yaml \
--policy.path=lerobot/smolvla_base \
--policy.push_to_hub=false \
--policy.repo_id=ruali/smolvla-submit-4types \
--rename_map='{"observation.images.top_rgb":"observation.images.camera1","observation.images.left_rgb":"observation.images.camera2","observation.images.right_rgb":"observation.images.camera3"}' \
2>&1 | tee logs/smolvla_submit_4types_bs48_30k.log
6.3 四类评测结果
评测使用自定义 custom_smolvla policy type,对四个类别分别跑 headless 评测。
top_short:
Total Episodes: 12
Average Return: 210.73 ± 79.87
Success Rate: 8.33%
比单类 30k 的 25% 还低。四类数据混训,top_short 被稀释了。
top_long:
Total Episodes: 12
Average Return: 165.41 ± 56.77
Success Rate: 50.00%
长袖表现显著好于短袖,可能是因为长袖的布料更多、折叠策略更明确。
pant_long:
Total Episodes: 12
Average Return: 119.94 ± 37.63
Success Rate: 16.67%
长裤比较平庸。Seen 实例基本都失败。
pant_short:
Total Episodes: 12
Average Return: 173.10 ± 105.91
Success Rate: 75.00%
短裤表现最好!Seen 实例 9/10 成功。
6.4 整体汇总
| 类别 | Success Rate |
|---|---|
| top_short | 8.33% |
| top_long | 50.00% |
| pant_long | 16.67% |
| pant_short | 75.00% |
6.5 提交自动化脚本
为了规整评测输出,我写了一个 tools/run_submission_eval.sh 一键跑完四类并汇总到 submission_results/rollout_results.txt。这个文件可以直接放进 Hugging Face 提交仓库。
7. 提交到 Hugging Face并且填写表单
我的baseline模型链接:ruali-dev/lehome-smolvla-submit-4types · Hugging Face
提交类型选 Hugging Face Submission。创建 repo ruali-dev/lehome-smolvla-submit-4types,放入:
pretrained_model/(完整 checkpoint)custom_smolvla_policy.pyrollout_results.txttrain_smolvla_submit.yamlREADME.md
最稳的上传方式:在服务器上打包 → scp 到本地 → 网页上传。
# 服务器上
cd ~/gpufree-data/lehome-challenge
mkdir -p hf_submit_bundle
cp -r outputs/train/smolvla_submit_4types/checkpoints/last/pretrained_model hf_submit_bundle/
cp scripts/eval_policy/custom_smolvla_policy.py hf_submit_bundle/
cp submission_results/rollout_results.txt hf_submit_bundle/
# 本地 PowerShell
scp -r root@服务器IP:~/gpufree-data/lehome-challenge/hf_submit_bundle .
表单按照官网表单填写并且整理代码,填完会收到回执。
8. 小结
30k 四类 baseline 的提交跑通了,但 top_short 8.33% 和 pant_long 16.67% 说明 30k 是不够的。pant_short 75% 说明模型确实学到了东西;关于参加这种“打榜”式的比赛的话,个人认为先交上一个baseline是必备工作,先跑通了流程后续的工作也会更有底气。