

摘要
在 LeHome Challenge 中,我在跑通 ACT baseline 之后尝试了 Diffusion Policy。结果不太理想——top_short 任务上 30k 成功率为 0%,50k 仅 16.67%。本文记录完整的尝试过程:从 DP smoke test 到长训、从发现左手抓取偏置到逐步 debug(policy 输出日志、环境执行日志、expert replay 对照、单件测试),以及最终判断——问题更可能是 DP rollout 不稳定而非数据或配置错误。同时也发现当时的实验环境代码基线落后官方 main,可能影响了 DP 的结果。
正文
1. 为什么试 DP
ACT baseline 跑通之后,top_short 拿到了 58.33%。既然流程跑通了,自然想试试看其他方法能不能拉高分数。Diffusion Policy 也是模仿学习领域的主流方法之一,官方也提供了开箱即用的 train_dp.yaml 配置,试一下的成本不高。而且这次租的是48G的L40,之前就没打过这么富裕的仗。
DP 训练时间比 ACT 长很多,必须用 tmux 挂后台。另外我不打算上来就训很久——先做个 smoke test 验证流程。
2. DP Smoke Test
2.1 配置
cd ~/lehome-challenge
cp configs/train_dp.yaml configs/train_dp_top_short_ruali.yaml
dataset:
repo_id: repo_dp_top_short_ruali
root: Datasets/example/top_short_merged
policy:
type: diffusion
device: cuda
push_to_hub: false
input_features:
observation.state:
type: STATE
shape: [12]
observation.images.top_rgb:
type: VISUAL
shape: [3, 480, 640]
observation.images.left_rgb:
type: VISUAL
shape: [3, 480, 640]
observation.images.right_rgb:
type: VISUAL
shape: [3, 480, 640]
output_features:
action:
type: ACTION
shape: [12]
output_dir: /root/gpufree-data/lehome-outputs/train/dp_top_short
batch_size: 32
steps: 10000
save_freq: 5000
log_freq: 100
wandb:
enable: false
batch_size 32 + 10k step,是一个比较稳妥的 smoke 配置。能跑完就说明环境没问题。
2.2 tmux 开训
tmux new -s lehome_dp
cd ~/lehome-challenge
source .venv/bin/activate
lerobot-train --config_path configs/train_dp_top_short_ruali.yaml \
2>&1 | tee /root/gpufree-data/lehome-outputs/logs/dp_top_short_train.log
退出不杀任务:Ctrl+b 然后按 d
回来查看:tmux attach -t lehome_dp
另开终端监控:
tail -f /root/gpufree-data/lehome-outputs/logs/dp_top_short_train.log
watch -n 5 nvidia-smi
2.3 Smoke 评测
python -m scripts.eval \
--policy_type lerobot \
--policy_path /root/gpufree-data/lehome-outputs/train/dp_top_short/checkpoints/last/pretrained_model \
--dataset_root Datasets/example/top_short_merged \
--garment_type top_short \
--num_episodes 1 \
--max_steps 300 \
--enable_cameras \
--save_video \
--video_dir /root/gpufree-data/lehome-outputs/eval/dp_top_short_smoke_gui \
--device cpu
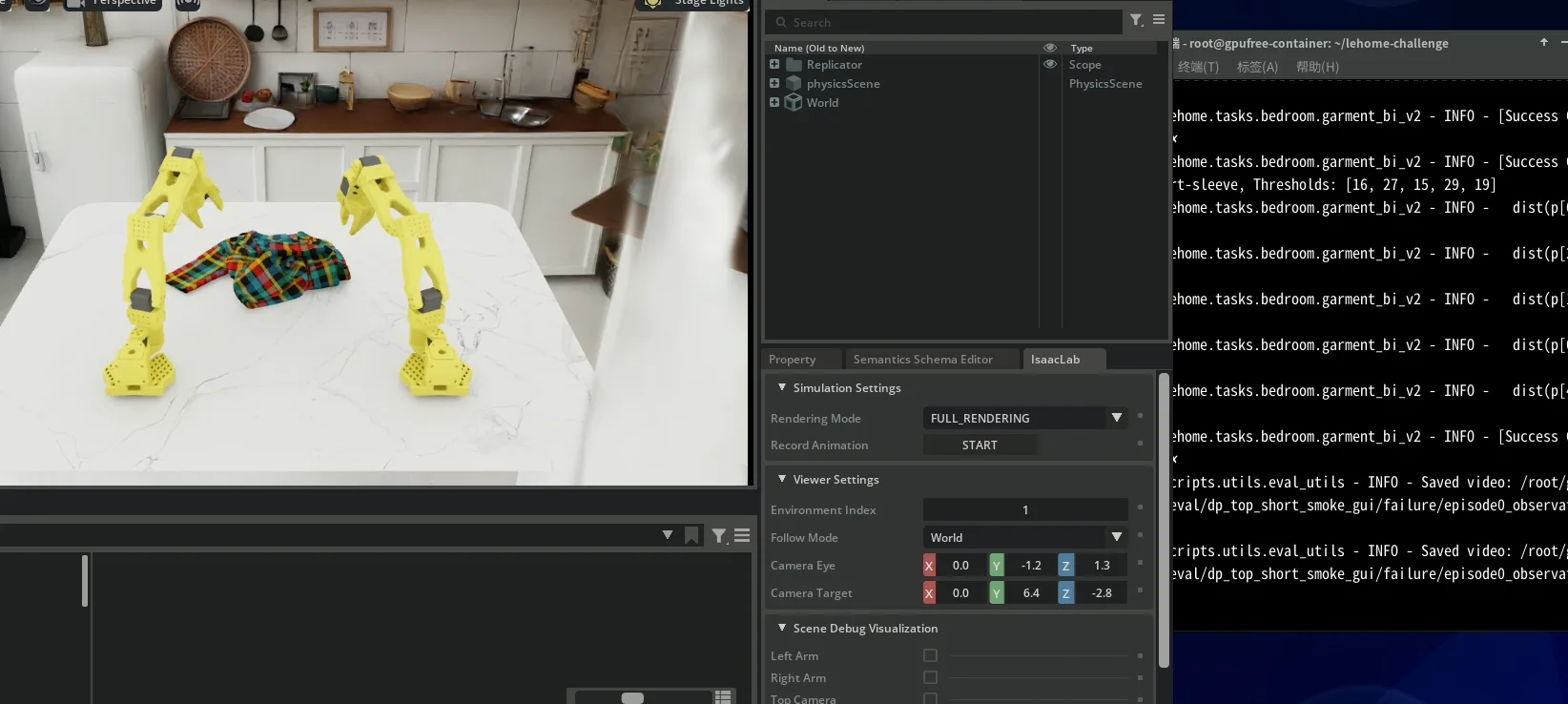
Smoke 评测看 Isaac Sim 面板,虽然失败率极高,但感觉"有潜力"——机械臂确实在朝衣服的方向运动,不是完全随机的。于是决定开 50k 长训。
3. DP 50k 训练
3.1 配置
cd ~/lehome-challenge
cp configs/train_dp_top_short_ruali.yaml configs/train_dp_top_short_ruali_50k.yaml
主要变化:steps: 50000,save_freq: 10000,其余不变。
3.2 训练
tmux new -s lehome_dp_long
cd ~/lehome-challenge
source .venv/bin/activate
lerobot-train --config_path configs/train_dp_top_short_ruali_50k.yaml \
2>&1 | tee /root/gpufree-data/lehome-outputs/logs/dp_top_short_50k_train.log
tmux 小技巧:怎么在 tmux 里往上翻
Ctrl+b 然后按 [
然后方向键/PageUp/PageDown 翻页,q 退出。这个能救命。
4. 结果:左手总是偏
4.1 带 GUI 评测
python -m scripts.eval \
--policy_type lerobot \
--policy_path /root/gpufree-data/lehome-outputs/train/dp_top_short_50k/checkpoints/last/pretrained_model \
--dataset_root Datasets/example/top_short_merged \
--garment_type top_short \
--num_episodes 1 \
--max_steps 300 \
--enable_cameras \
--save_video \
--video_dir /root/gpufree-data/lehome-outputs/eval/dp_top_short_50k_gui \
--device cpu
直接看 Isaac Sim 画面——左手总是抓偏一个位置。右手感觉挺稳的,但左手就是不对。
4.2 无头完整评测
cd ~/lehome-challenge
source .venv/bin/activate
python -m scripts.eval \
--policy_type lerobot \
--policy_path /root/gpufree-data/lehome-outputs/train/dp_top_short_50k/checkpoints/last/pretrained_model \
--dataset_root Datasets/example/top_short_merged \
--garment_type top_short \
--num_episodes 1 \
--enable_cameras \
--save_video \
--video_dir /root/gpufree-data/lehome-outputs/eval/dp_top_short_50k \
--device cpu \
--headless
结果让我有点崩溃。50k 步训练下来,全 failed 也太离谱了。
4.3 30k 也照样偏
为了排除"50k 训练出了什么奇怪问题",又跑了 30k checkpoint 的评测:
Total Episodes: 12
Average Return: 162.83 ± 40.93
Success Rate: 0.00%
Per-Garment:
Top_Short_Seen_0: 0.00%
Top_Short_Seen_1: 0.00%
...
Top_Short_Unseen_1: 0.00%
12 个 episode,12 个 0%。但是 Average Return 有 162.83——这很微妙,说明奖励函数认为它在做正确的事,但几何判定标准认为它没做到。
5. 开始 Debug
5.1 排除"数据本身就左手偏"
先看 expert replay:
cd ~/lehome-challenge
source .venv/bin/activate
python -m scripts.dataset_sim replay \
--dataset_root Datasets/example/top_short_merged \
--num_replays 1 \
--disable_depth \
--device cpu \
--enable_cameras
专家回放正常——左右手动作对称,抓取准确。数据没问题,问题出在策略端。
5.2 加 Policy 输出日志
在 scripts/eval_policy/lerobot_policy.py 里,找到 batch_action = self.policy.select_action(batch_obs),在它后面插入:
self._dbg_step = getattr(self, "_dbg_step", 0) + 1
if self._dbg_step % 20 == 0:
act = batch_action[0].detach().float().cpu().numpy()
logger.info(
f"[POLICY DEBUG] step={self._dbg_step} "
f"left={np.round(act[:6], 3).tolist()} "
f"right={np.round(act[6:], 3).tolist()}"
)
这层日志看的是:DP 自己吐出来的 12 维动作,左 6 维和右 6 维是不是已经很不对称。
5.3 加环境执行日志
在 source/lehome/lehome/tasks/bedroom/garment_bi_v2.py 找到 self.actions = self.action_scale * actions.clone(),在后面插入:
self._dbg_env_step = getattr(self, "_dbg_env_step", 0) + 1
if self._dbg_env_step % 20 == 0:
act = self.actions[0].detach().float().cpu().numpy()
logger.info(
f"[ENV DEBUG] step={self._dbg_env_step} "
f"left={np.round(act[:6], 3).tolist()} "
f"right={np.round(act[6:], 3).tolist()}"
)
这层看的是:进入环境、乘完 action_scale 之后,左右手是否才开始明显失衡。
5.4 单件测试
为了细粒度观察,我把测试列表改成只测一件衣服:
cp Assets/objects/Challenge_Garment/Release/Release_test_list.txt \
/root/gpufree-data/Release_test_list.backup.txt
nano Assets/objects/Challenge_Garment/Release/Release_test_list.txt
nano 操作:Ctrl+O 保存,回车确认,Ctrl+X 退出。把文件内容改成单个 Top_Short_Seen_x。
5.5 Debug 结论
结论 1:不是"左右手切片写反"
POLICY DEBUG 和 ENV DEBUG 都能看到左右 6 维动作在正常流动。不是那种明显的"左手拿到右手通道"的低级错误。
结论 2:问题更像是 DP 输出不稳定 / 模式跳变
从单件衣服日志看,DP 不是一直固定"左手抓偏同一个常数位置",而是:
- 某些时刻一侧动作比较稳定,另一侧突然跳到另一种模式
- 这种跳变有时发生在左手,有时发生在右手
- 但整体 rollout 又长期过不了最终几何阈值
具体例子:
- step 20 时 policy 左右都还算正常
- 到 step 120,left 明显跳到另一种模式,而 right 还比较像"正常抓取"
- 到 step 360、440,right 也会出现明显不同于前面稳定段的输出
ENV DEBUG里也能看到执行前的 joint target 会跟着这些模式切换变化
所以更准确地说,不是单纯"左手通道坏了",而是:DP 在这个任务上学出了不够稳定的双臂动作分布,左手更容易先暴露这个问题。
结论 3:reward 在涨,但 success 条件一直没被真正满足
单件衣服跑完:Return = 117.98,Success = False。
中间多次 success check 都是:
dist(p[0], p[1])、dist(p[4], p[5])这两条能过- 但
dist(p[0], p[4])、dist(p[2], p[3])、dist(p[1], p[5])长期远超阈值
这说明它不是"完全不会动",而是一直在做某种看起来有进展的动作,但没把衣服真正收拢到目标折叠几何关系里。
6. 发现另一个问题:代码基线落后
在 debug DP 的过程中,顺便检查了镜像里的仓库版本:
git log --oneline -5
git fetch origin
git log --oneline origin/main -10
发现:
- 镜像里的仓库基线是
2953e2f,分支main - fetch 之后,官方当前
origin/main已经到了23127e9——落后官方 main 一串提交 - 当前工作目录不是干净的
2953e2f,而是旧基线 + 一堆本地改动 + 自己的 YAML 配置
缺的几条很相关的上游更新:
32b5359 fix: unify garment success check coordinate space across CPU/GPU (#56)6b54226 Add image processing configurations in train_dp.yaml (#58)9c35592 Add .to(device) in image preprocessing to speed up eval (#52)
这些都和 success check / DP / eval 直接相关。
所以回答那个灵魂拷问——"不会我现在的镜像和官方还有 DataWhale 两个都不一样吧?"
很可能就是。 更准确地说,我当时实验环境的代码基线是一个旧官方版本,不是最新 main。这个差异对 DP 评测结果的影响有多大,因为没有在更新后重新跑对比实验,无法量化。但它至少是一个不可忽视的变量。
7. 最终判断
综合以上:
- expert 正常
- ACT 明显能成功(58.33%)
- DP 30k 是 0%
- DP 50k 只有 16.67%
- 单件 debug 里 policy/环境都存在模式跳变
我会把这条线定性为:
当前这套 DP baseline 在 LeHome top_short 上不好用,问题更像 policy rollout 不稳定,而不是数据集下错、左右手切片写反、或者单纯步数不够。
有可能用更新后的代码基线 + 更多步数 + 调参能改善,但考虑到比赛截止时间和一份 L40 的算力限制,我没有继续在这条线上投入。转向下一个方法。
事后话:
再看到smolVLA scaling的表现之后,回想DP,也可能是DP就是训练不够,50k step对DP还是太少了。不过怎么说呢,这次比赛整体上是4类不同衣服,有限的机时给VLA来说确实比DP划算。