

摘要
本文记录了我以个人身份参加 ICRA 2026 LeHome Challenge 的完整过程。从环境搭建、数据准备,到 ACT / Diffusion Policy / SmolVLA / pi0.5 四条技术路线的尝试与取舍,再到最终方案的选择与提交。重点不是晒成绩,而是记录真实参赛者在有限时间和资源下的路线决策过程与工程踩坑经历。
正文
LeHome 这一系列文章属于"先完成项目,后补写记录"。
整个 3、4 月份事情比较多:一边准备和参加 LeHome Challenge,一边还在处理升学、实习等各种事项,所以当时只来得及把训练、评测和提交流程先跑完,没有及时整理成文章。到了五一假期,我先在 B 站发布了 LeHome 的效果展示视频;节后又来到合肥,在某9研究院孵化企业实习,担任R&D Intern。前几天一直在适应新的工作环境和上手研发任务,直到今天周日放假,才终于有时间把 LeHome 的过程系统整理出来。
由于这次项目过程比较长,涉及 ACT baseline、Diffusion Policy、SmolVLA 微调、pi0.5 尝试、最终提交和榜单复盘等内容,所以我没有把所有内容塞进一篇长文,而是拆成一个系列。本文作为总览篇,会先梳理整个项目的背景、路线选择、最终结果和个人反思。更具体的环境配置、训练过程和模型尝试,会放在系列文章的其他篇目中。
如果你是第一次看这个系列,可以直接从本文开始了解整体脉络;如果更关心具体实现,也可以从 ACT baseline 那篇开始,按照文末的系列文章索引依次阅读。
打这个比赛的原因,ACT篇里面也已经讲过了:大体就是考研下岸了,但日子还得过。毕业前总得做点东西,不然简历上的"机器人工程专业"就真的只是一行字了。
大概三月中下旬,无意间刷到了 LeHome Challenge @ ICRA 2026——一个仿真环境下的衣物折叠比赛,主题是 Garment Manipulation Skill Learning in Household Scenarios。用双臂机械臂在 Isaac Sim 里操控衣服做折叠任务,正好和我的毕设方向有交集。寻思着把这个做了也能给毕设减减负,于是上车。
关于参赛身份:我一个人。没有团队、没有实验室资源、没有专属 GPU 服务器。这决定了我的策略——优先选择能跑通、能用、能在截止前交上去的方案,而不是追求单指标最优。
2. 任务介绍
比赛官方仓库:lehome-official/lehome-challenge。
核心任务是用两个 LeRobot SO-101 双臂机械臂在 Isaac Sim 仿真环境中,对四类衣物进行折叠:
top_short:短袖上衣top_long:长袖上衣pant_short:短裤pant_long:长裤
每类衣物有 10 件 Seen 实例 + 2 件 Unseen 实例,评测时每个 episode 跑一条轨迹。成功判定不是靠肉眼看视频,而是检查衣服网格上若干关键检查点之间的距离是否满足阈值。具体的成功判定逻辑在 ACT 篇里展开。
3. 算力环境
我手里没有能跑 Isaac Sim 的 GPU。正好网上有个算力自由平台,有官方预装镜像(后面还是得自配环境),配置:
- GPU:L40 48G
- CPU:14 核
- 内存:128G
- 系统盘:30G(停机清空)
- 数据盘:50G(按量付费)
平台网页远程桌面很卡,感觉就是普通 VNC,正经干活还是靠 SSH。数据盘计费大概是 1GB 一天 0.01 元,系统盘小而贵,所以数据集、训练产出、checkpoint 全部挂数据盘是基本操作。
4. 四条技术路线概览
我的探索顺序:
4.1 ACT(Action Chunking Transformer)
最先跑通。 作为官方 baseline,用它验证了环境可用性、数据加载、训练、评测、视频导出的完整流程。在 top_short 单任务上,30k step 达到 58.33% 的成功率。环境排障花了不少时间——Isaac Lab 安装报 ModuleNotFoundError: No module named 'isaaclab',根因是 setuptools 82 移除了 pkg_resources,导致 flatdict==4.0.1 构建失败。
详见:LeHome ACT Baseline 跑通记录:从环境排障到训练、评测与导出视频 - 硅基之瞳
4.2 Diffusion Policy
跑了,但不好用。 top_short 上 30k 成功率为 0%,50k 为 16.67%。左手抓取存在明显偏置,策略输出存在模式跳变——不是"完全不会动",而是偶尔表现得像模像样,但整体过不了几何阈值。
花了相当多的时间 debug:加 policy/env 级别的 debug 日志、单件衣服测试、检查 expert replay。结论是 DP rollout 稳定性问题,而不是数据或配置错误。此外还发现镜像里的仓库基线落后官方 main 一串提交(含 DP 相关的修复),这可能也影响了结果。
详见:LeHome 跑 Diffusion Policy:不太理想的尝试 - 硅基之瞳
4.3 SmolVLA
最终提交方案。 从 10k smoke → 30k top_short → 30k 四类 baseline → 50k → 70k → 90k 逐步 scale。最后选择 70k 提交。
最大工程坑点:训练时用 rename_map 把数据集的 top_rgb/left_rgb/right_rgb 映射成了 SmolVLA 期望的 camera1/camera2/camera3,但官方评测路径里没有 rename_map 处理,导致评测时模型收不到任何图像。最终写了一个 CustomSmolVLAPolicy 绕过去。
详见:LeHome SmolVLA 微调:从 Smoke Test 到 Baseline 提交 - 硅基之瞳和 Scaling 的力量与边界:LeHome SmolVLA 从 30k 到 90k 的训练复盘 - 硅基之瞳
4.4 pi0.5
想冲分但没来得及。 前置步骤包括:安装 OpenPI 的 transformers_replace 补丁、降级 transformers 到 4.53.2、处理 Google 模型授权(paligemma)。LoRA 微调 sanity check 通过后,分别跑了 30k、150k、270k(约 1 epoch)。视频效果"初具人形,但还是悬空"——手臂会朝正确方向移动,但始终没有稳定抓取。
到截止前没有跑出可用结果,最终未作为主力方案。
详见:LeHome 尝试 pi0.5:依赖地狱、LoRA 微调与截止前的放弃 - 硅基之瞳
5. 最终选择:SmolVLA 70k
70k vs 90k 在四类衣物上的汇总:
| 类别 | 70k Success Rate | 90k Success Rate |
|---|---|---|
| top_long | 58.33% | 41.67% |
| top_short | 25.00% | 25.00% |
| pant_long | 41.67% | 33.33% |
| pant_short | 83.33% | 83.33% |
70k 在 top_long 和 pant_long 上领先,pant_short 持平,top_short 持平(25% 的惨淡成绩两个 checkpoint 都没救回来)。90k 在 top_long 上出现了明显的性能回退(41.67% vs 58.33%),综合判断选 70k。
一个直观规律:裤子比衣服好叠,短裤最好叠(83.33%),短袖最难(25%)。这很合理——短袖布料更少,折叠策略更不直观,而短裤的"对折"动作相对明确。
6. 提交
提交物:
- Hugging Face Model Repo:ruali-dev/lehome-smolvla-submit-4types-70k · Hugging Face
- pretrained_model、custom_smolvla_policy.py、rollout_results.txt
- 四个类别的完整评测日志
小插曲:榜单结果与日志核对
比赛结束后,我其实已经不太执着于名次了。毕竟这次是个人参赛,自己也只是本科生,没有团队和额外资源;而且 3、4 月份还同时夹杂着升学、实习、毕业设计等事情,真正能集中投入比赛的时间并不算多。
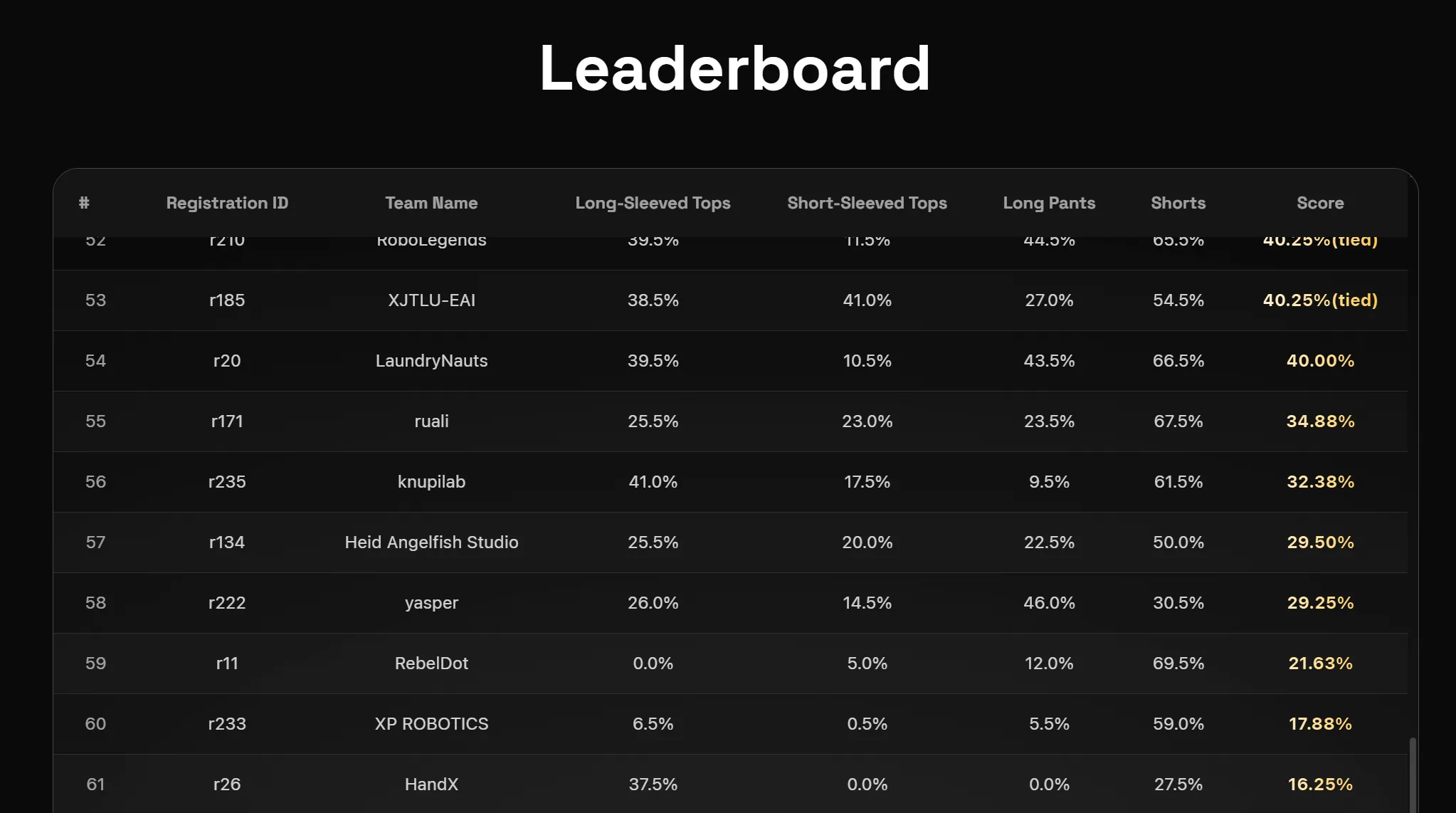
不过在 70k 模型训练完成后,我根据本地评测和视频观感,原本预期最终成绩大概能到 40% 左右。今天在 Discord 看到官方发布仿真赛道榜单后,我去官网查了一下,发现最终成绩是 34.88%,低于自己的预期。
一开始我怀疑是不是最终提交的 70k 模型没有被评测,而是评到了之前较早提交的模型。于是我给官方发邮件,请求查看 evaluation logs,并附上了 4 月 30 日最终提交的 Google Forms 回执和 Hugging Face 仓库链接。
官方这边回复得很及时,也很耐心。第一次发来的日志确实对应的是早期提交,后来他们又帮我重新核对并发来了两次提交的评测日志。最终确认:官网榜单上的 34.88% 成绩,确实对应 4 月 30 日提交的 SmolVLA 70k 模型。
这下也就没什么好纠结的了。结果没有达到预期,主要还是时间不够、经验不足,以及自己对本地视频观感和官方评测指标之间的差距估计不充分。视频里看起来"更像会折了",并不代表最终关键点距离一定能稳定满足 success check 的阈值。
这次也算是给我上了一课:本地看视频觉得"好像已经学会了",和官方 benchmark 真的给分,是两回事。尤其是衣物折叠这种可变形物体任务,动作看起来像,不代表关键点真的折到了目标位置。最后分数不高确实有点失落,但至少这次完整走完了训练、提交、榜单、日志核对和结果复盘的流程。

7. 反思
关于方法选择。 如果重新来,我会更早开始 SmolVLA,跳过 DP 或者只做快速验证。但不做 DP 就不会知道它在这个任务上到底有什么问题,这个排除过程本身也是经验。
关于 pi0.5。 不是 pi0.5 不好,是我没给它足够时间去调。从依赖冲突到 transformers 补丁再到 Google 授权,环境搭建就很消耗精力了。一个人的时候,"能跑通"的优先级远高于"可能更强"。
关于算力。 L40 48G 跑 SmolVLA(batch_size 48)和 DP(batch_size 32)都够用,但 pi0.5 LoRA 微调 batch_size 只能开到 1,因为 3.6B 参数量的 backbone 显存吃紧。270k step 耗时非常长。如果再有机会,会考虑更大 GPU 或多卡。
关于工程。 表面是算法比赛,实际大量时间在:修环境依赖、写自定义 policy 适配评测、搭评测脚本、打 debug 日志、排查 rollout 问题。我觉得这才是真实的科研工程日常,跟论文里"我们直接用了 XXX 框架"之间有巨大的 gap。
关于一个人。 好处是决策快、没有沟通成本。坏处是容易在某个方向闷头走太远。pi0.5那条路我确实花了太久才决定放弃。
系列文章索引
- B. [ACT 篇]:LeHome ACT Baseline 跑通记录:从环境排障到训练、评测与导出视频 - 硅基之瞳
- C. [DP 篇]:LeHome 跑 Diffusion Policy:不太理想的尝试 - 硅基之瞳
- D. [SmolVLA 30k + Baseline 提交篇]:LeHome SmolVLA 微调:从 Smoke Test 到 Baseline 提交 - 硅基之瞳
- E. [pi0.5 篇]:LeHome 尝试 pi0.5:依赖地狱、LoRA 微调与截止前的放弃 - 硅基之瞳
- F. [SmolVLA 70k/90k 对比篇]:Scaling 的力量与边界:LeHome SmolVLA 从 30k 到 90k 的训练复盘 - 硅基之瞳